"Speech-Driven Facial Reenactment Using Conditional Generative Adversarial Networks":
https://arxiv.org/abs/1803.07461v1
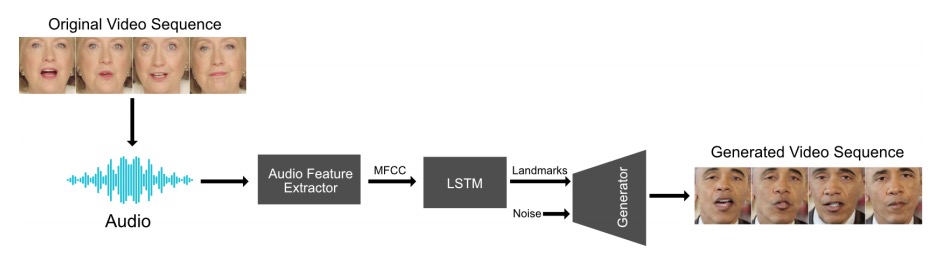

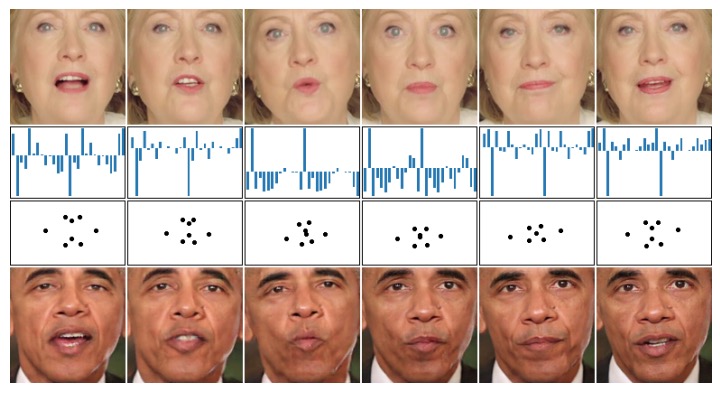
Abstract: "We present a novel approach to generating photo-realistic images of a face with accurate lip sync, given an audio input. By using a recurrent neural network, we achieved mouth landmarks based on audio features. We exploited the power of conditional generative adversarial networks to produce highly-realistic face conditioned on a set of landmarks. These two networks together are capable of producing sequence of natural faces in sync with an input audio track."