-
Intellectual Osmosis
"The literary/intellectual osmosis rule: We believe books change you, even from a distance. A book unread is still an idea encountered. Proximity counts." - samim

-
Ian Fleming’s typical day at his estate in Jamaica where he wrote all his James Bond stories. Ian Fleming died at 56.



-
Schwinger Limit
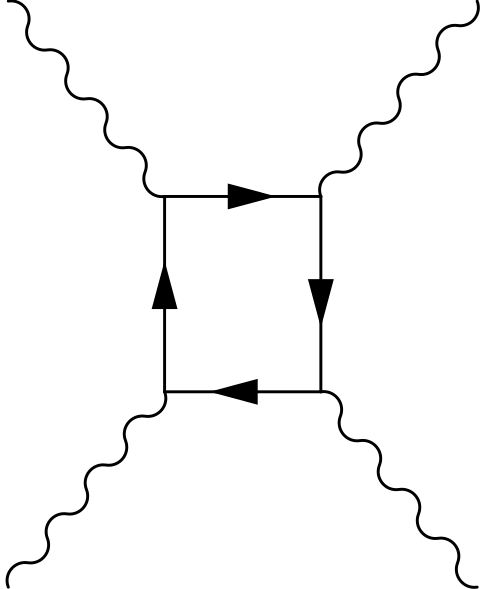
The Schwinger limit is a critical threshold in quantum electrodynamics representing the maximum intensity an electromagnetic field can reach before the vacuum itself becomes unstable and spontaneously produces matter. Named after Nobel laureate Julian Schwinger, it defines the point where space-time fields turn non-linear and tear virtual electron-positron pairs into real particles.
"The vacuum is not empty; it is a lively playground of virtual particles being born and destroyed continually." - Julian Schwinger from his landmark 1951 paper, “On Gauge Invariance and Vacuum Polarization”
-
Lorentz oscillator model

The Lorentz oscillator model is a classical physics framework that describes how light interacts with matter by treating bound electrons in an atom as a driven, damped harmonic oscillator. Proposed by Hendrik Lorentz, the model represents the electron as a small mass connected to a massive, stationary nucleus via a hypothetical spring (obeying Hooke's Law) and a damper.
-
Deforestation in the Maranhão state, Brazil, in 2016 - When ever you hear of some capitalist breakout success, it's usually 1-3 hops from causing this..