ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders (Audio Samples)
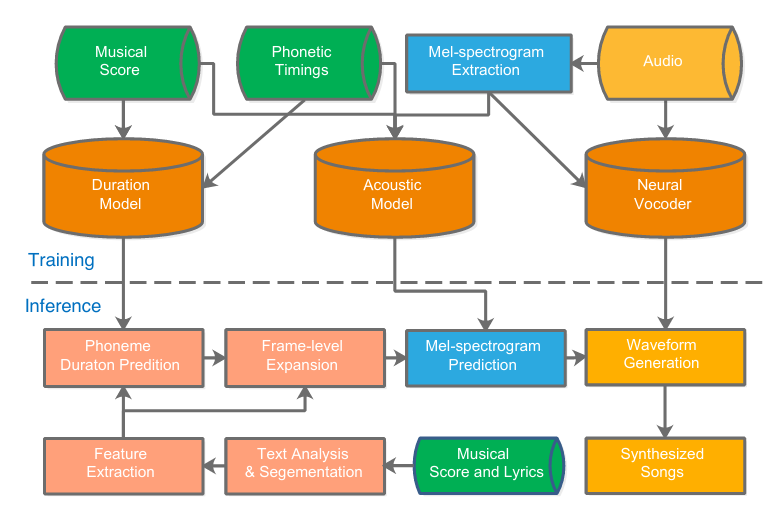
This paper presents ByteSing, a Chinese singing voice synthesis (SVS) system based on duration allocated Tacotron-like acoustic models and WaveRNN neural vocoders. Different fromthe conventional SVS models, the proposed ByteSing employs Tacotron-like encoder-decoder structures as the acoustic models, in which the CBHG models and recurrent neural networks (RNNs) are explored as encoders and decoders respectively.