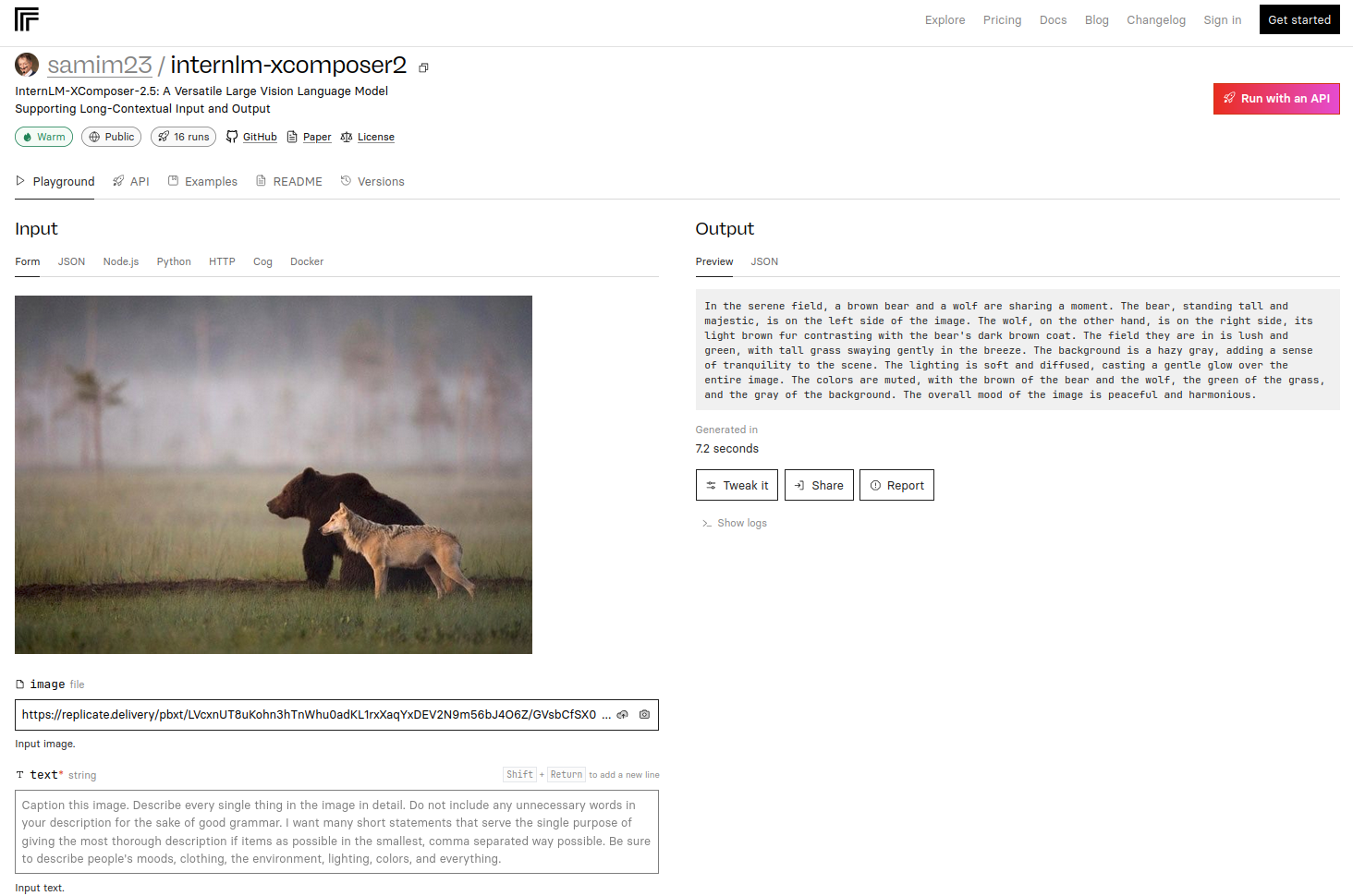
I ported "InternLM-XComposer-2.5 - A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output" by @wjqdev et al - to @replicate. It excels in various img-2-text tasks, achieving GPT-4V level capabilities with just a 7B LLM backend