tag > Music
-
Expressive Speech Synthesis with Tacotron: #ML #Music
https://research.googleblog.com/2018/03/expressive-speech-synthesis-with.htmlTensorflow Implementation of Expressive Tacotron:
https://github.com/Kyubyong/expressive_tacotron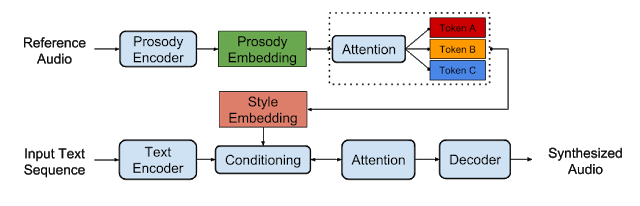
-
EEGsynth: "Converting real-time EEG into sounds, music and visual effects": http://www.eegsynth.org/ code: https://github.com/eegsynth/eegsynth #BCI #Music

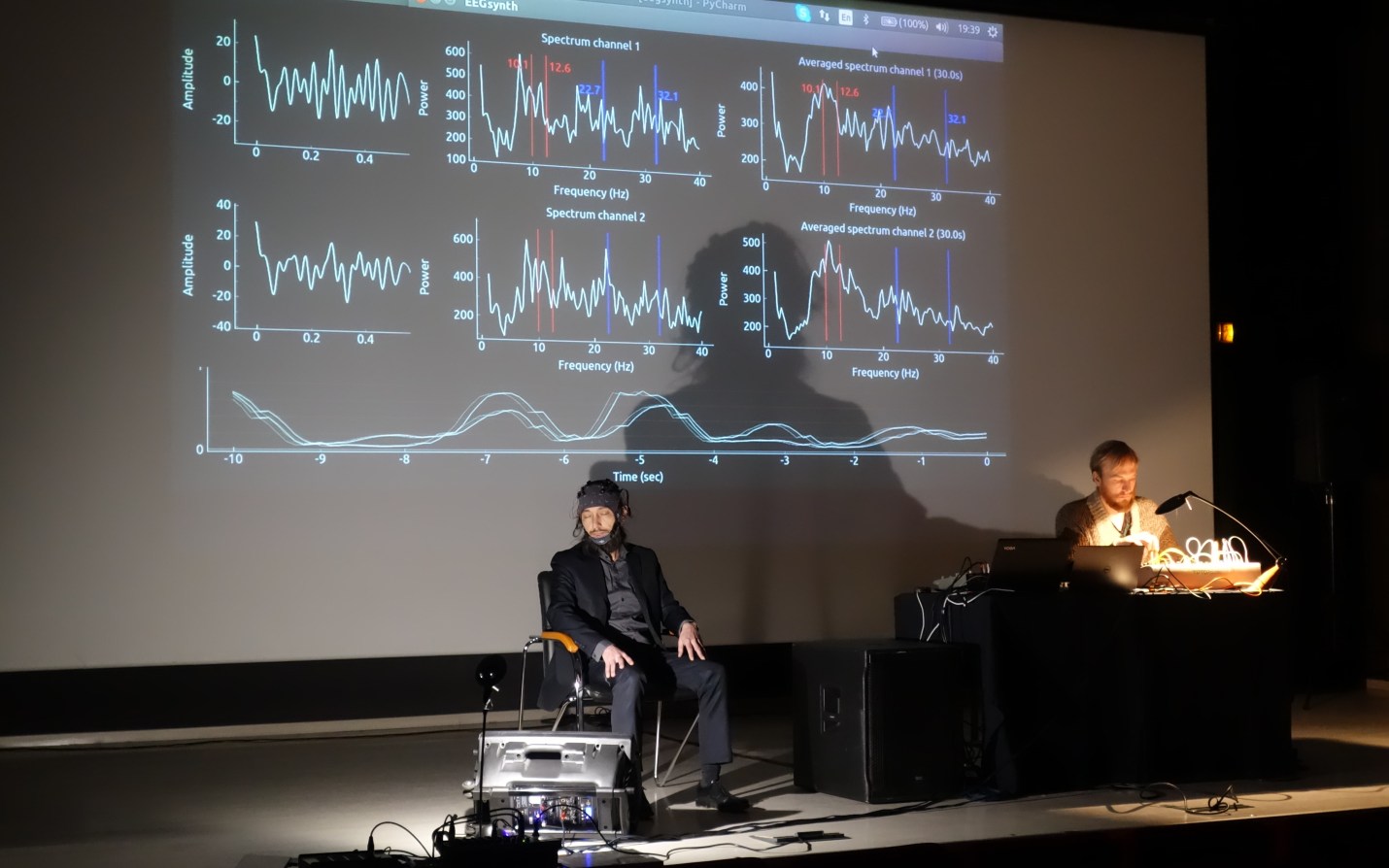

The EEGsynth is an open-source Python codebase that provides a real-time interface between devices for electrophysiological recordings (e.g. EEG, EMG and ECG) and analogue and digital devices (e.g. MIDI, games and analogue synthesizers). This allows one to use electrical brain/body activity to flexibly control devices in real-time, for what are called (re)active and passive brain-computer-interfaces (BCIs), biofeedback and neurofeedback.
-
What’s wrong with CNNs and spectrograms for audio processing? #ML #Music
https://towardsdatascience.com/whats-wrong-with-spectrograms-and-cnns-for-audio-processing-311377d7ccd -
With Musical Cryptography, Composers Can Hide Messages in Their Melodies:
https://www.atlasobscura.com/articles/musical-cryptography-codes #Music
-
Vicious Cycle - a short animation featuring a group of little helpless robots performing a range of repetitive functions. by Michael Marczewski: https://vimeo.com/198802302
-
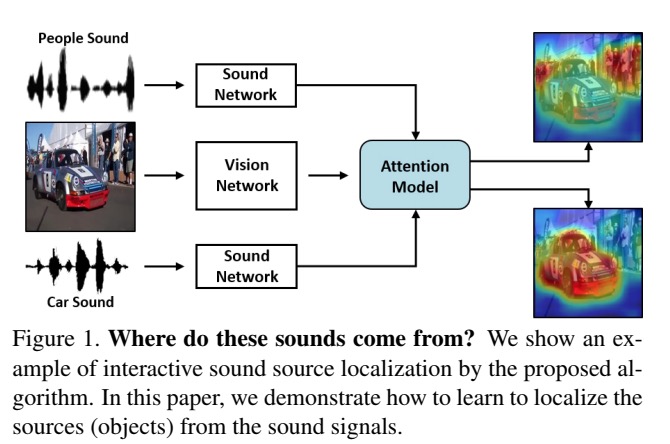
Learning to Localize Sound Source in Visual Scenes: https://arxiv.org/abs/1803.03849
-
Expressive Speech Synthesis with Tacotron: #ML #Generative #Music
https://research.googleblog.com/2018/03/expressive-speech-synthesis-with.html
Research Paper: https://google.github.io/tacotron/publications/global_style_tokens...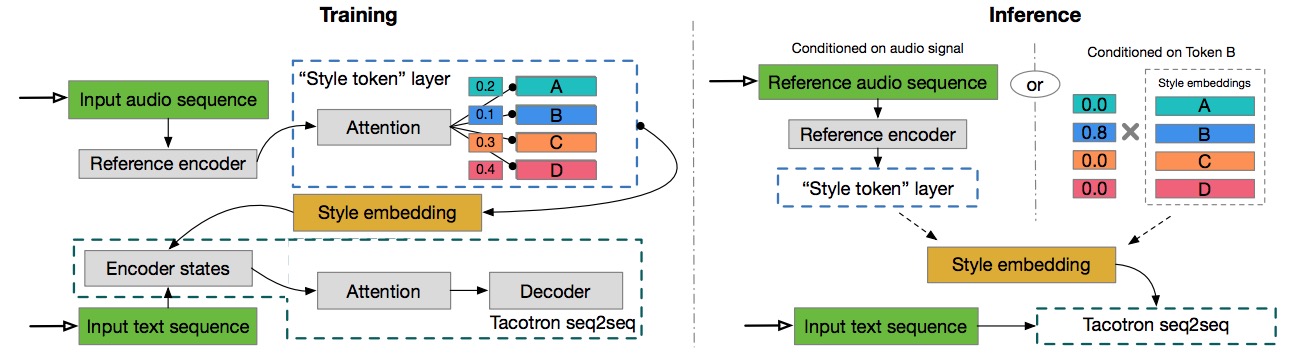
-
Two new #Generative #Music javascript libraries, flux & midio:
fluX: "A nano API for generative music in the browser": https://github.com/pd3v/fluX
midio: "a web-based generative synthesizer radio": https://github.com/evangipson/midio -
Melody Mixer: Using Deeplearn.js to Mix Melodies in the Browser:
https://medium.com/@torinblankensmith/melody-mixer-using-deeplearn-js-to-mi..
Experiment: https://melodymixer.withgoogle.com/ai/melody-mixer/view/
-
Neural Voice Cloning with a Few Samples:
https://arxiv.org/abs/1802.06006v2 Audio Demos: https://audiodemos.github.io/
-
Visual history of Intermorphic's involvement in #Generative #Music over almost 30 years:
http://cdm.link/newswires/intermorphic-gives-us-visual-history-involvement-generative-music-almost-30-years/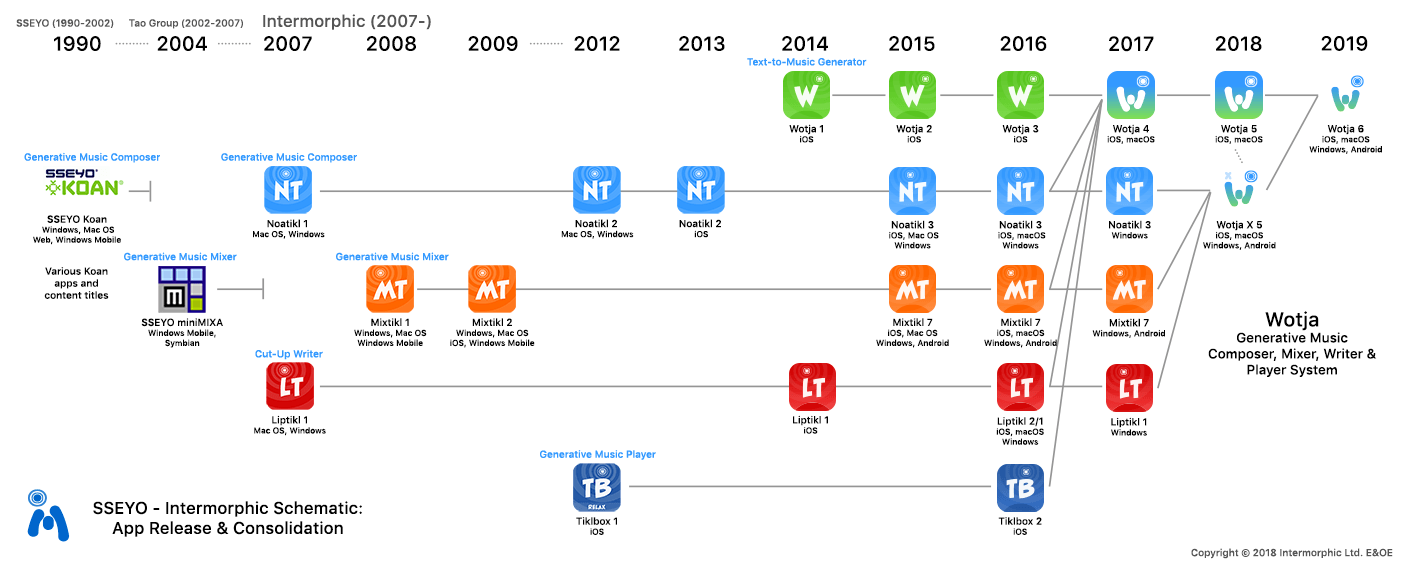
-
Beat-Blender uses machine learning to create music with interactive latent spaces. Built with deeplearnjs + Magenta: https://experiments.withgoogle.com/ai/beat-blender
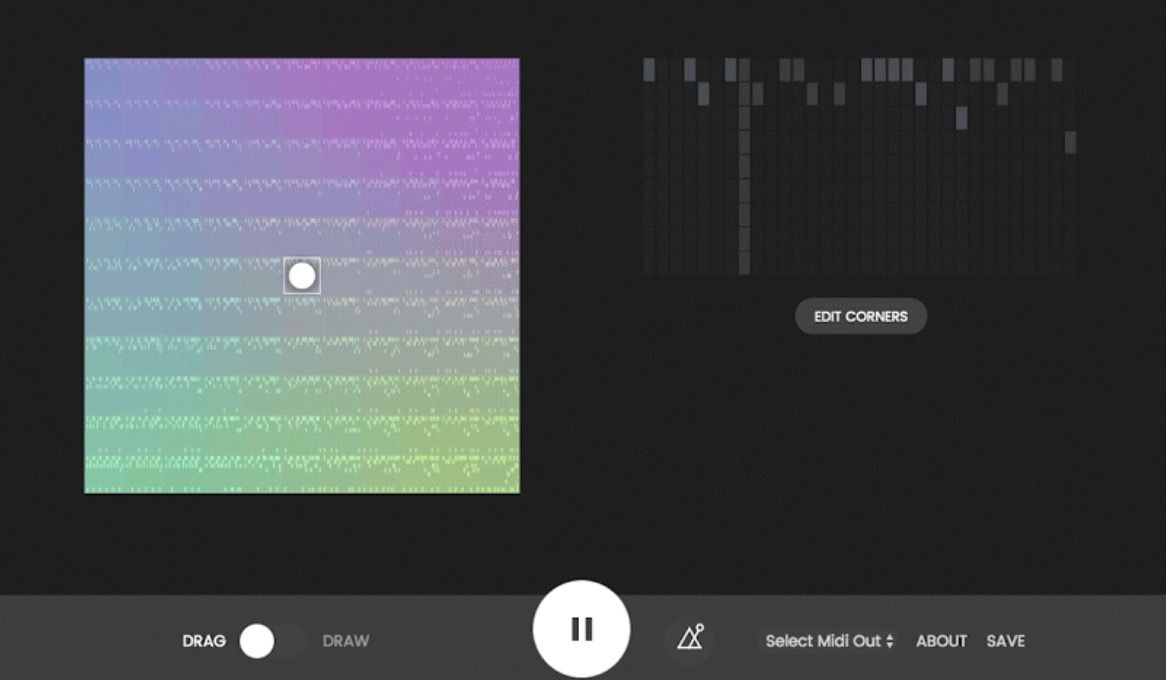
-
Upload a image, the network generates a fitting natural soundscape:
Demo: http://imaginarysoundscape2.qosmo.jp/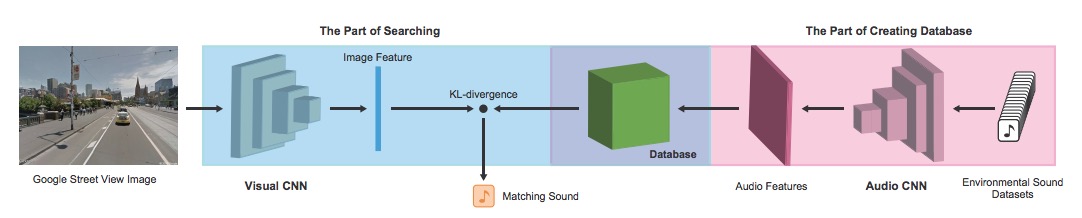
-
"Modelling Affect for Horror Soundscapes": #ML #Generative #Music #Emotion http://antoniosliapis.com/papers/modelling_affect_for_horror_soundscapes.pdf
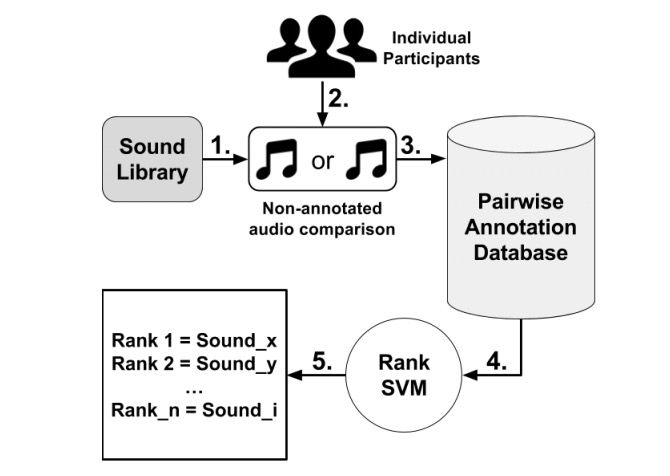
Abstract: "The feeling of horror within movies or games relies on the audience’s perception of a tense atmosphere — often achieved through sound accompanied by the on-screen drama — guiding its emotional experience throughout the scene or game-play sequence. These progressions are often crafted through an a priori knowledge of how a scene or game-play sequence will playout, and the intended emotional patterns a game director wants to transmit. The appropriate design of sound becomes even more challenging once the scenery and the general context is autonomously generated by an algorithm. Towards realizing sound-based affective interaction in games this paper explores the creation of computational models capable of ranking short audio pieces based on crowdsourced annotations of tension, arousal and valence. Affect models are trained via preference learning on over a thousand annotations with the use of support vector machines, whose inputs are low-level features extracted from the audio assets of a comprehensive sound library. The models constructed in this work are able to predict the tension, arousal and valence elicited by sound, respectively, with an accuracy of approximately 65%, 66% and 72%."
-
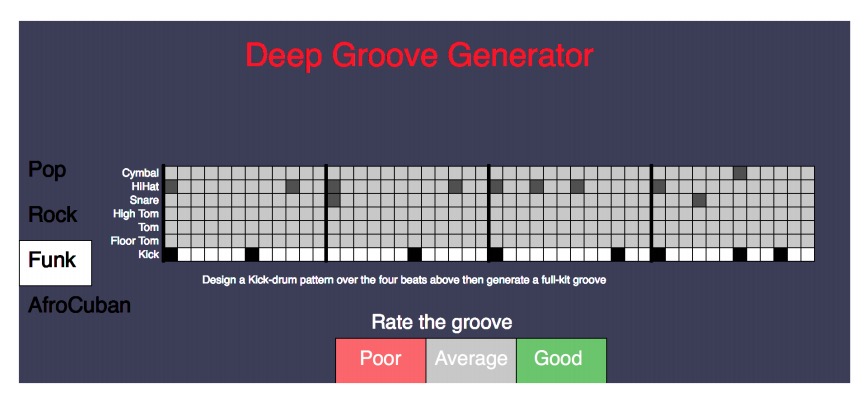
"Talking Drums: Generating drum grooves with neural networks": https://arxiv.org/pdf/1706.09558.pdf #ML #Generative #Music
-
#Music of the night
-
Uakti - I Ching