tag > Science
-
Today in Magnetization Dynamics: The ferromagnetic resonance phenomenon
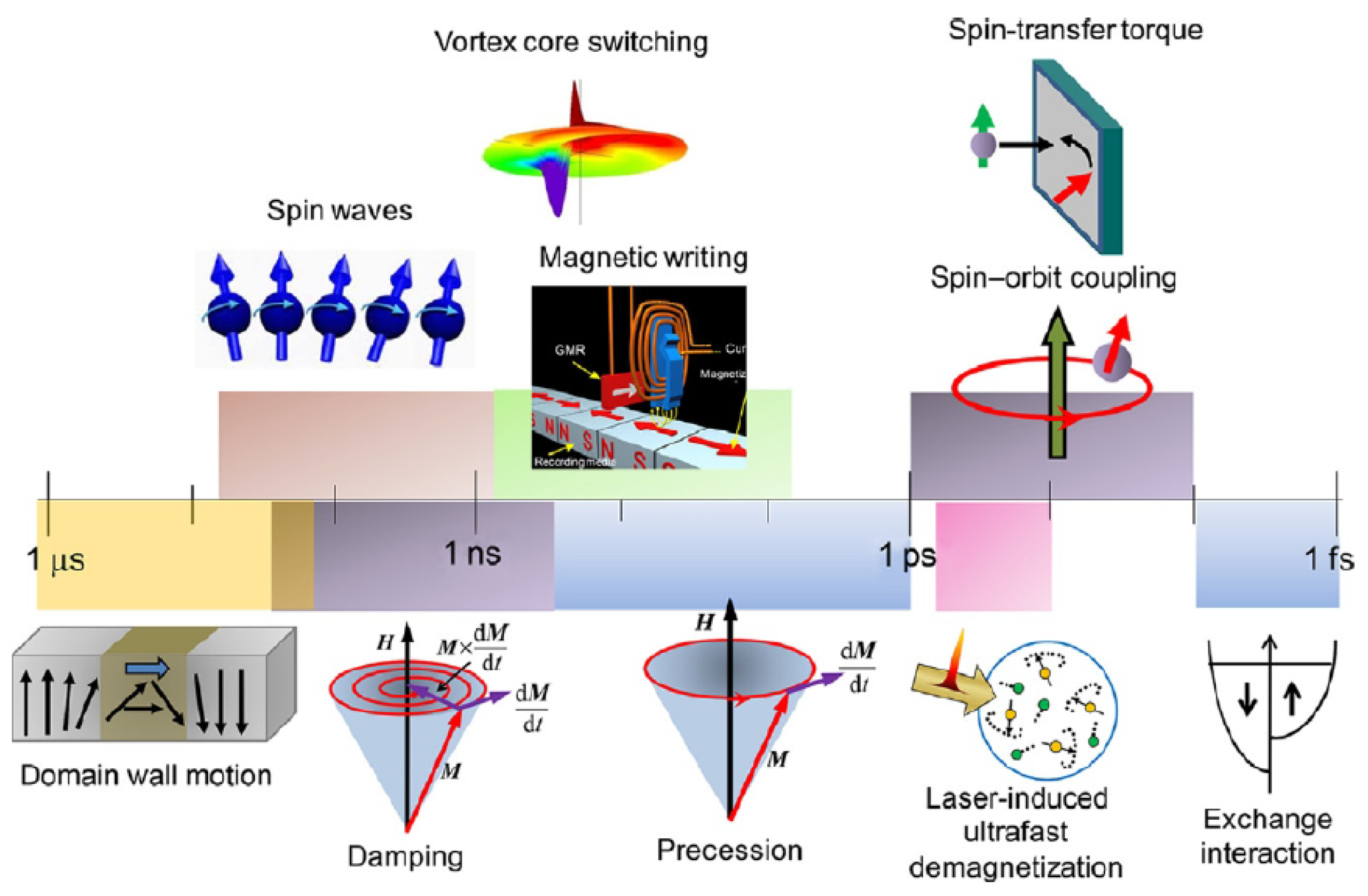
Diagram showing different time scales characteristic of various types of magnetization dynamics The ferromagnetic resonance phenomenon is the basis of an experimental technique that measures the precessional motion of the magnetization vector of a ferromagnet in an external static magnetic field. This experimental technique is a powerful tool for analyzing the magnetic properties of ferromagnets and allows the determination of anisotropy constants, see, e.g.,1. Knowledge of these constants, in turn, enables the determination of the sample’s spatial distribution of the magnetic free energy at resonance.
-
"What are the most important problems in your field? Why aren’t you working on them?" - Richard Hamming, paraphrased from his talk “You and Your Research” (1986)

-
Kozyrev’s classic idea that time has flow, density, and direction is back — this time in modern physics, as Möbius time lattices: mirrors that don’t just reflect light, but fold the timeline. Non-classical time evolution is no longer sci-fi. It’s lab-ready. Are you paying attention?


-
Richard Feynman’s blackboard at time of his death

Richard Feynman’s “Last Blackboard” Analysis
Richard Feynman’s “last blackboard” is famous both for what it literally shows—his handwriting, partial notes, and equations—and for the broader symbolism people have attached to it. Below is a more detailed breakdown of each section and why it’s significant.
1. The Top Lines
“What I cannot create I do not understand.”
Possible Meaning:
This line encapsulates Feynman’s deep conviction that genuine understanding in science (and particularly in physics) comes from being able to re‐derive, rebuild, or “create” an idea from the ground up. If you can construct a phenomenon or theory step by step yourself, you truly understand it.
Historical Note:
There’s sometimes debate over the exact source or phrasing of this quote. It’s often attributed directly to Feynman, though some trace its spirit to Wittgenstein or other thinkers. Regardless, it strongly reflects Feynman’s style: he was known to insist on re‐deriving known results and prided himself on not just taking existing solutions at face value.
“Know how to solve every problem that has been solved.”
Possible Meaning:
This line underscores another key part of Feynman’s philosophy: he believed that one should be intimately familiar with the repertoire of known physics problems and their solutions. By learning how previous problems were solved, you build a mental toolkit for tackling new problems.
Feynman’s Approach:
He famously re‐derived major results on his own, from quantum mechanics to electrodynamics, often because he wanted a fresh, intuitive understanding. “Know how to solve every problem that has been solved” is a succinct way of saying: “Master the canon of known problems; don’t rely on secondhand knowledge.”
2. The “To Learn” Section (Center/Right)
This part is partly erased or smudged, but it appears to be a short list of research topics or curiosities Feynman wanted to explore further:
To learn: Beta ... Prob. Knot 2-D Hall (real Temps? real tamps?) Non Linear Classical ...
“Beta … Prob.”
Some interpret this as “Beta anomaly problem” or “Beta asymptotics problem.” In physics, “beta” often refers to the beta function (e.g., in quantum field theory, the beta function describes how coupling constants change with energy scale).
“Knot”
This may indicate an interest in knot theory or topological ideas (e.g., the study of how knots behave in physical systems). Feynman was known to be intrigued by seemingly abstract mathematical ideas that might shed light on physical phenomena.
“2-D Hall”
Possibly referring to the two‐dimensional Hall effect, including the quantum Hall effect discovered in the early 1980s, which was a hot research topic at the time.
“(real temps?)”
It’s unclear whether he wrote “real temps” or “real tamps.” One guess is “real temperatures,” meaning real‐temperature (finite‐temperature) effects in a 2D system.
“Non Linear Classical …”
Possibly “Nonlinear classical theory,” “Nonlinear classical physics,” or “Nonlinear classical hydrodynamics.” Feynman had broad interests, including fluid dynamics, chaos, and related nonlinear phenomena.
These lines give us a snapshot of what was on his mind or “to‐do list” near the end of his life—a set of advanced or emerging problems in physics and mathematics he still wanted to investigate.
3. The Bottom‐Right Equations
f = U(R, a) g = (4 – 2) U(1 + 2) f = –21 r^(1/2) (…)
Meaning/Context:
These are fragments of some functional relationships or potential expansions. It’s not entirely clear which specific problem he was working on. It could be a quick jotting of an idea about a function U(·) depending on variables R and a.
“g = (4 – 2) U(1 + 2)” looks almost like a placeholder or a simplified expression (4 – 2 = 2). He might have been playing with scaling or specific numeric values in a problem.
“f = –21 r^(1/2) …” suggests some proportionality to √r. He may have been testing an approximation, a dimensional analysis, or a boundary condition. Because the chalkboard is incomplete, we only see a snippet.
While many have speculated, the bottom‐right corner doesn’t clearly match any single well‐known Feynman derivation. It may have been a side calculation or an outline for a discussion. The partial nature is part of what makes the blackboard so poignant—it’s a window into a process rather than a finished product.
4. Symbolic Significance
- A “Snapshot” in Time: The blackboard is not necessarily Feynman’s grand “final statement”; it’s just what happened to be on his board when he died in February 1988. Yet, it’s often treated as a distillation of his mindset and style.
-
Feynman’s Legacy:
- Curiosity: Always exploring new ideas (“To learn” list).
- Hands‐On Understanding: “What I cannot create I do not understand.”
- Mastery of Canonical Problems: “Know how to solve every problem that has been solved.”
- Playfulness with Equations: The partial functions at the bottom reflect the tinkering approach Feynman was famous for.
5. Where You Can See It
Location: The blackboard is preserved at the California Institute of Technology (Caltech), where Feynman spent most of his career. It has become an iconic piece of scientific memorabilia, akin to Einstein’s chalkboard at the University of Oxford.
In Summary
Feynman’s final blackboard highlights his enduring themes:
- Creative approach to science (you must be able to “build” or re‐derive ideas).
- Comprehensive approach to learning (knowing every solved problem).
- Restless curiosity (his “To learn” list spanning knot theory, 2D physics, nonlinear systems, etc.).
- Hands‐on method of notation and tinkering (the half‐finished equations at the bottom).
Though it’s just a casual snapshot of his notes, it has taken on an almost mythic status, reflecting the ethos of a physicist who believed in understanding by doing, a dedication to constant learning, and a willingness to explore ideas at the frontier.
-
Scientists Produced a Particle of Light That Simultaneously Accessed 37 Different Dimensions
- The Greenberger–Horne–Zeilinger (GHZ) paradox describes how quantum theory cannot be described by local realistic descriptions.
- A new study takes this GHZ paradox to new heights to see just how non-classical the quantum world can get.
- In the process, their experiment included photons in 37 dimensions, taking science even further down this strange quantum rabbit hole with the hopes of finding applications in these high-dimensional systems.
-
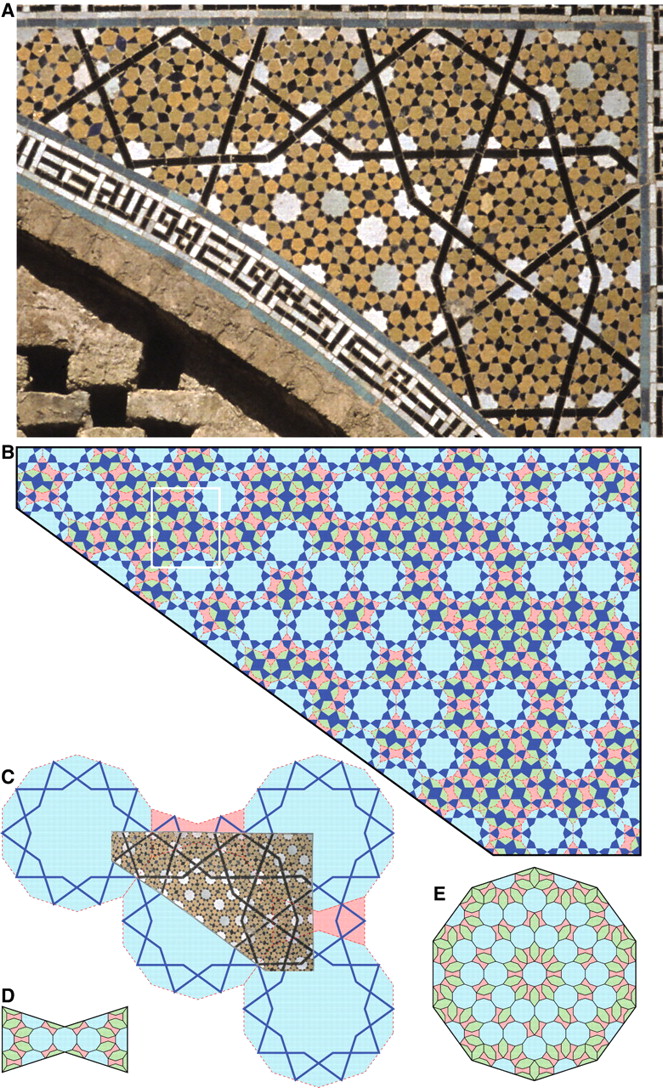
Islamic mathematicians & artists discovered the "Penrose tilings" of Quasicrystals hundreds of years before western scientists.
Image 1: Girih-tile subdivision found in the decagonal girih pattern on a spandrel from the Darb-i Imam shrine, Isfahan, Iran (1453 C.E.). A subdivision rule to construct perfect quasi-crystalline tilings has been identified.
Image 2: Quasicrystal type patterns above an arch in the Abbasid al-Mustansiriyya Madrasa in Baghdad, Iraq, 1227


-
Earth has 4 days simultaneously each rotation. You erroneously measure time from 1 corner.
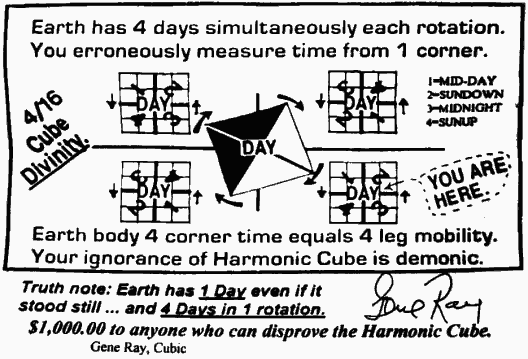
-
What does the square root of "-1" and fairies have in common? They’re both imaginary… but that doesn't mean they aren't useful! 🧚

-
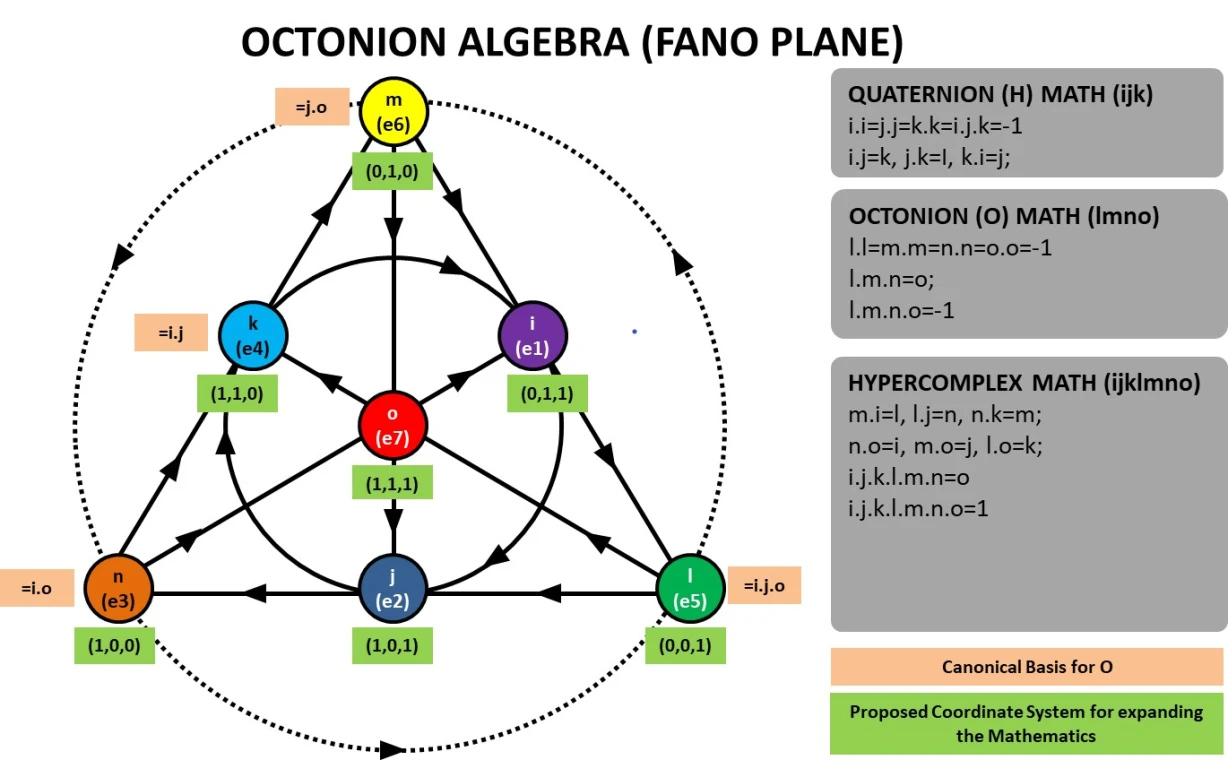
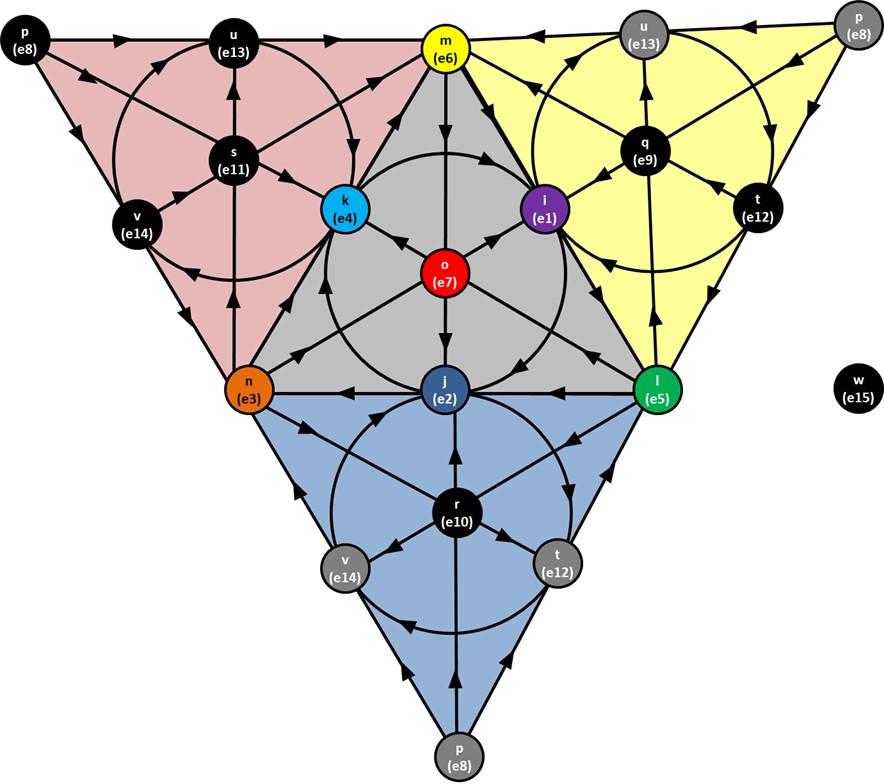
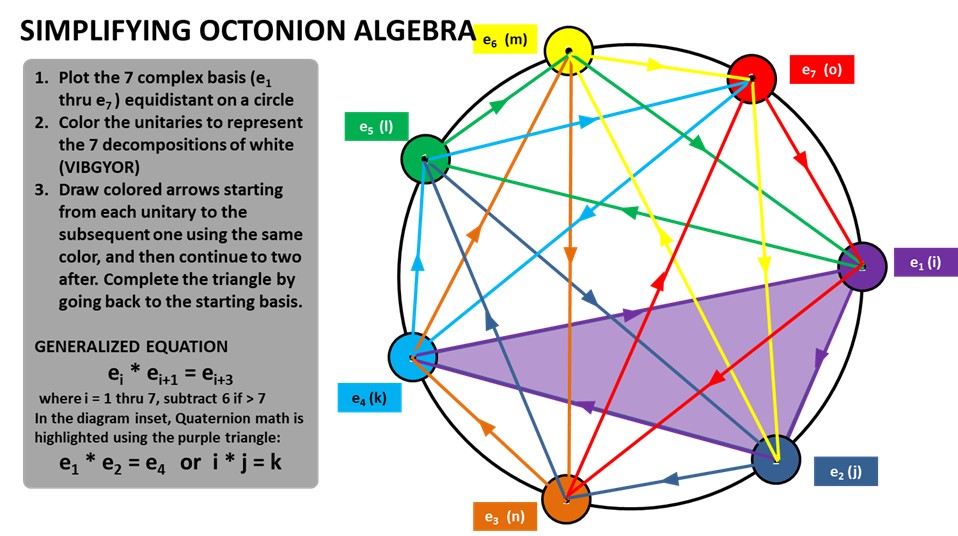
Octonions - eight-dimensional hypercomplex numbers used in theoretical physics with a number of counterintuitive properties.

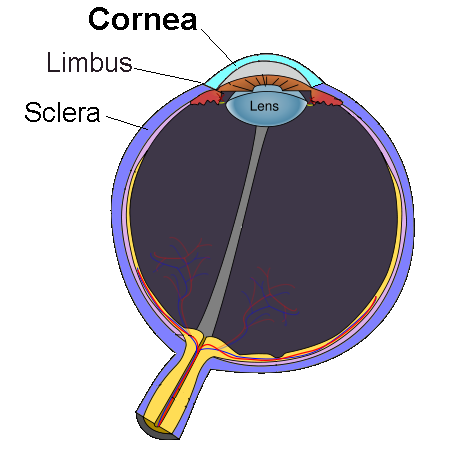
Octonions can be understood as self-referential biquaternions that naturally model phenomena like vision - imagine a sphere (like an eye) that maintains its geometric properties while having both transparent and opaque regions. Just as your eye uses its lens to transform 3D space onto a 2D retinal surface and then encodes this into 1D neural signals, octonions provide a mathematical framework for this kind of dimensional reduction through self-reference. The self-dual property of octonions (being their own mirror image mathematically) enables them to simultaneously represent both the spatial domain (like the physical structure of the eye) and the frequency domain (like the neural encoding of visual information), making them uniquely suited for modeling systems that need to transform between different dimensional representations while preserving essential geometric properties.
The Peculiar Math That Could Underlie the Laws of Nature
New findings are fueling an old suspicion that fundamental particles and forces spring from strange eight-part numbers called “octonions.”

The Octonion Math That Could Underpin Physics
“The real numbers are the dependable breadwinner of the family, the complete ordered field we all rely on. The complex numbers are a slightly flashier but still respectable younger brother: not ordered, but algebraically complete. The quaternions, being noncommutative, are the eccentric cousin who is shunned at important family gatherings. But the octonions are the crazy old uncle nobody lets out of the attic: they are nonassociative.” – John Baez
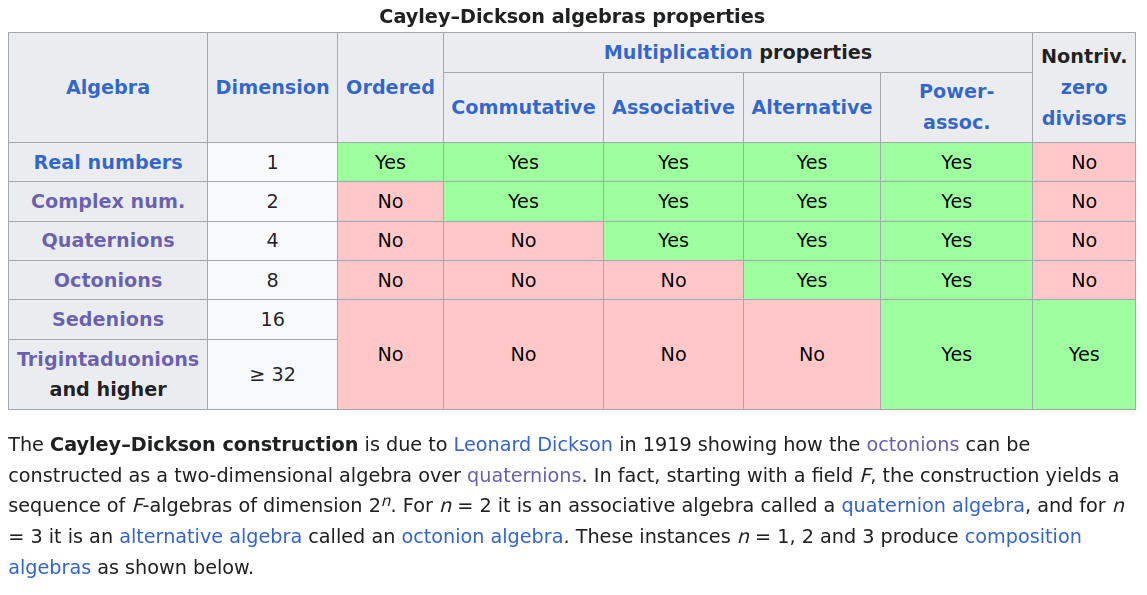
Fun Fact: Octonions are the last number system in the Cayley-Dickson construction that still forms a division algebra (meaning you can divide by non-zero elements). If you go beyond octonions (to sedenions), you lose even more properties!
Hypercomplex Math and the Standard Model
-
VortexNet: Neural Computing through Fluid Dynamics
Abstract

We present VortexNet, a novel neural network architecture that leverages principles from fluid dynamics to address fundamental challenges in temporal coherence and multi-scale information processing. Drawing inspiration from von Karman vortex streets, coupled oscillator systems, and energy cascades in turbulent flows, our model introduces complex-valued state spaces and phase coupling mechanisms that enable emergent computational properties. By incorporating a modified Navier–Stokes formulation—similar to yet distinct from Physics-Informed Neural Networks (PINNs) and other PDE-based neural frameworks—we implement an implicit form of attention through physical principles. This reframing of neural layers as self-organizing vortex fields naturally addresses issues such as vanishing gradients and long-range dependencies by harnessing vortex interactions and resonant coupling. Initial experiments and theoretical analyses suggest that VortexNet supports integration of information across multiple temporal and spatial scales in a robust and adaptable manner compared to standard deep architectures.
Introduction
Traditional neural networks, despite their success, often struggle with temporal coherence and multi-scale information processing. Transformers and recurrent networks can tackle some of these challenges but might suffer from prohibitive computational complexity or vanishing gradient issues when dealing with long sequences. Drawing inspiration from fluid dynamics phenomena—such as von Karman vortex streets, energy cascades in turbulent flows, and viscous dissipation—we propose VortexNet, a neural architecture that reframes information flow in terms of vortex formation and phase-coupled oscillations.
Our approach builds upon and diverges from existing PDE-based neural frameworks, including PINNs (Physics-Informed Neural Networks), Neural ODEs, and more recent Neural Operators (e.g., Fourier Neural Operator). While many of these works aim to learn solutions to PDEs given physical constraints, VortexNet internalizes PDE dynamics to drive multi-scale feature propagation within a neural network context. It is also conceptually related to oscillator-based and reservoir-computing paradigms—where dynamical systems are leveraged for complex spatiotemporal processing—but introduces a core emphasis on vortex interactions and implicit attention fields.
Interestingly, this echoes the early example of the MONIAC and earlier analog computers that harnessed fluid-inspired mechanisms. Similarly, recent innovations like microfluidic chips and neural networks highlight how physical systems can inspire new computational paradigms. While fundamentally different in its goals, VortexNet demonstrates how physical analogies can continue to inform and enrich modern computation architectures.
Core Contributions:
- PDE-based Vortex Layers: We introduce a modified Navier–Stokes formulation into the network, allowing vortex-like dynamics and oscillatory phase coupling to emerge in a complex-valued state space.
- Resonant Coupling and Dimensional Analysis: We define a novel Strouhal-Neural number (Sn), building an analogy to fluid dynamics to facilitate the tuning of oscillatory frequencies and coupling strengths in the network.
- Adaptive Damping Mechanism: A homeostatic damping term, inspired by local Lyapunov exponent spectrums, stabilizes training and prevents both catastrophic dissipation and explosive growth of activations.
- Implicit Attention via Vortex Interactions: The rotational coupling within the network yields implicit attention fields, reducing some of the computational overhead of explicit pairwise attention while still capturing global dependencies.
Core Mechanisms
-
Vortex Layers:
The network comprises interleaved “vortex layers” that generate counter-rotating activation fields. Each layer operates on a complex-valued state space
S(z,t), wherezrepresents the layer depth andtthe temporal dimension. Inspired by, yet distinct from PINNs, we incorporate a modified Navier–Stokes formulation for the evolution of the activation:∂S/∂t = ν∇²S - (S·∇)S + F(x)Here,
νis a learnable viscosity parameter, andF(x)represents input forcing. Importantly, the PDE perspective is not merely for enforcing physical constraints but for orchestrating oscillatory and vortex-based dynamics in the hidden layers. -
Resonant Coupling:
A hierarchical resonance mechanism is introduced via the dimensionless Strouhal-Neural number (Sn):
Sn = (f·D)/A = φ(ω,λ)In fluid dynamics, the Strouhal number is central to describing vortex shedding phenomena. We reinterpret these variables in a neural context:
- f is the characteristic frequency of activation
- D is the effective layer depth or spatial extent (analogous to domain or channel dimension)
- A is the activation amplitude
- φ(ω,λ) is a complex-valued coupling function capturing phase and frequency shifts
- ω represents intrinsic frequencies of each layer
- λ represents learnable coupling strengths
By tuning these parameters, one can manage how quickly and strongly oscillations propagate through the network. The Strouhal-Neural number thus serves as a guiding metric for emergent rhythmic activity and multi-scale coordination across layers.
-
Adaptive Damping:
We implement a novel homeostatic damping mechanism based on the local Lyapunov exponent spectrum, preventing both excessive dissipation and unstable amplification of activations. The damping is applied as:
γ(t) = α·tanh(β·||∇L||) + γ₀Here,
||∇L||is the magnitude of the gradient of the loss function with respect to the vortex layer outputs,αandβare hyperparameters controlling the nonlinearity of the damping function, andγ₀is a baseline damping offset. This dynamic damping helps keep the network in a regime where oscillations are neither trivial nor diverging, aligning with the stable/chaotic transition observed in many physical systems.
Key Innovations
- Information propagates through phase-coupled oscillatory modes rather than purely feed-forward paths.
- The architecture supports both local and non-local interactions via vortex dynamics and resonant coupling.
- Gradient flow is enhanced through resonant pathways, mitigating vanishing/exploding gradients often seen in deep networks.
- The system exhibits emergent attractor dynamics useful for temporal sequence processing.
Expanded Numerical and Implementation Details
To integrate the modified Navier–Stokes equation into a neural pipeline, VortexNet discretizes
S(z,t)over time steps and spatial/channel dimensions. A lightweight PDE solver is unrolled within the computational graph:-
Discretization Strategy: We employ finite differences or
pseudo-spectral methods depending on the dimensionality of
S. For 1D or 2D tasks, finite differences with periodic or reflective boundary conditions can be used to approximate spatial derivatives. - Boundary Conditions: If the data is naturally cyclical (e.g., sequential data with recurrent structure), periodic boundary conditions may be appropriate. Otherwise, reflective or zero-padding methods can be adopted.
-
Computational Complexity: Each vortex layer scales
primarily with
O(T · M)orO(T · M log M), whereTis the unrolled time dimension andMis the spatial/channel resolution. This can sometimes be more efficient than explicitO(n²)attention when sequences grow large. -
Solver Stability: To ensure stable unrolling, we maintain a
suitable time-step size and rely on the adaptive damping mechanism.
If
νorfare large, the network will learn to self-regulate amplitude growth viaγ(t). - Integration with Autograd: Modern frameworks (e.g., PyTorch, JAX) allow automatic differentiation through PDE solvers. We differentiate the discrete update rules of the PDE at each layer/time step, accumulating gradients from output to input forces, effectively capturing vortex interactions in backpropagation.
Relationship to Attention Mechanisms
While traditional attention mechanisms in neural networks rely on explicit computation of similarity scores between elements, VortexNet’s vortex dynamics offer an implicit form of attention grounded in physical principles. This reimagining yields parallels and distinctions from standard attention layers.
1. Physical vs. Computational Attention
In standard attention, weights are computed via:
A(Q,K,V) = softmax(QK^T / √d) VIn contrast, VortexNet’s attention emerges via vortex interactions within
S(z,t):A_vortex(S) = ∇ × (S·∇)SWhen two vortices come into proximity, they influence each other’s trajectories through the coupled terms in the Navier–Stokes equation. This physically motivated attention requires no explicit pairwise comparison; rotational fields drive the emergent “focus” effect.
2. Multi-Head Analogy
Transformers typically employ multi-head attention, where each head extracts different relational patterns. Analogously, VortexNet’s counter-rotating vortex pairs create multiple channels of information flow, with each pair focusing on different frequency components of the input, guided by their Strouhal-Neural numbers.
3. Global-Local Integration
Whereas transformer-style attention has
O(n²)complexity for sequence lengthn, VortexNet integrates interactions through:- Local interactions via the viscosity term
ν∇²S - Medium-range interactions through vortex street formation
- Global interactions via resonant coupling
φ(ω, λ)
These multi-scale interactions can reduce computational overhead, as they are driven by PDE-based operators rather than explicit pairwise calculations.
4. Dynamic Memory
The meta-stable states supported by vortex dynamics serve as continuous memory, analogous to key-value stores in standard attention architectures. However, rather than explicitly storing data, the network’s memory is governed by evolving vortex fields, capturing time-varying context in a continuous dynamical system.
Elaborating on Theoretical Underpinnings
Dimensionless analysis and chaotic dynamics provide a valuable lens for understanding VortexNet’s behavior:
- Dimensionless Groups: In fluid mechanics, groups like the Strouhal number (Sn) and Reynolds number clarify how different forces scale relative to each other. By importing this idea, we condense multiple hyperparameters (frequency, amplitude, spatial extent) into a single ratio (Sn), enabling systematic tuning of oscillatory modes in the network.
-
Chaos and Lyapunov Exponents: The local Lyapunov exponent
measures the exponential rate of divergence or convergence of trajectories
in dynamical systems. By integrating
||∇L||into our adaptive damping, we effectively constrain the system at the “edge of chaos,” balancing expressivity (rich oscillations) with stability (bounded gradients). - Analogy to Neural Operators: Similar to how Neural Operators (e.g., Fourier Neural Operators) learn mappings between function spaces, VortexNet uses PDE-like updates to enforce spatiotemporal interactions. However, instead of focusing on approximate PDE solutions, we harness PDE dynamics to guide emergent vortex structures for multi-scale feature propagation.
Theoretical Advantages
- Superior handling of multi-scale temporal dependencies through coupled oscillator dynamics
- Implicit attention and potentially reduced complexity from vortex interactions
- Improved gradient flow through resonant coupling, enhancing deep network trainability
- Inherent capacity for meta-stability, supporting multi-stable computational states
Reframing neural computation in terms of self-organizing fluid dynamic systems allows VortexNet to leverage well-studied PDE behaviors (e.g., vortex shedding, damping, boundary layers), which aligns with but goes beyond typical PDE-based or physics-informed approaches.
Future Work
-
Implementation Strategies:
Further development of efficient PDE solvers for the modified Navier–Stokes
equations, with an emphasis on numerical stability,
O(n)orO(n log n)scaling methods, and hardware acceleration (e.g., GPU or TPU). Open-sourcing such solvers could catalyze broader exploration of vortex-based networks. -
Empirical Validation:
Comprehensive evaluation on tasks such as:
- Long-range sequence prediction (language modeling, music generation)
- Multi-scale time series analysis (financial data, physiological signals)
- Dynamic system and chaotic flow prediction (e.g., weather or turbulence modeling)
- Architectural Extensions: Investigating hybrid architectures that combine VortexNet with convolutional, transformer, or recurrent modules to benefit from complementary inductive biases. This might include a PDE-driven recurrent backbone with a learned attention or gating mechanism on top.
- Theoretical Development: Deeper mathematical analysis of vortex stability and resonance conditions. Establishing stronger ties to existing PDE theory could further clarify how emergent oscillatory modes translate into effective computational mechanisms. Formal proofs of convergence or stability would also be highly beneficial.
-
Speculative Extensions: Fractal Dynamics, Scale-Free Properties, and Holographic Memory
-
Fractal and Scale-Free Dynamics: One might incorporate wavelet or multiresolution expansions in the PDE solver to natively capture fractal structures and scale-invariance in the data. A more refined “edge-of-chaos” approach could dynamically tune
νandλusing local Lyapunov exponents, ensuring that VortexNet remains near a critical regime for maximal expressivity. - Holographic Reduced Representations (HRR): By leveraging the complex-valued nature of VortexNet’s states, holographic memory principles (e.g., superposition and convolution-like binding) could transform vortex interactions into interference-based retrieval and storage. This might offer a more biologically inspired alternative to explicit key-value attention mechanisms.
-
Fractal and Scale-Free Dynamics: One might incorporate wavelet or multiresolution expansions in the PDE solver to natively capture fractal structures and scale-invariance in the data. A more refined “edge-of-chaos” approach could dynamically tune
Conclusion
We have introduced VortexNet, a neural architecture grounded in fluid dynamics, emphasizing vortex interactions and oscillatory phase coupling to address challenges in multi-scale and long-range information processing. By bridging concepts from partial differential equations, dimensionless analysis, and adaptive damping, VortexNet provides a unique avenue for implicit attention, improved gradient flow, and emergent attractor dynamics. While initial experiments are promising, future investigations and detailed theoretical analyses will further clarify the potential of vortex-based neural computation. We believe this fluid-dynamics-inspired approach can open new frontiers in both fundamental deep learning research and practical high-dimensional sequence modeling.
Code
This repository contains toy implementations of some of the concepts introduced in this research.