tag > Generative
-
Mark Zuckerberg reads "Industrial Society and Its Future" (Speech Synthesis)
-
Text-based Editing of Talking-head Video
See as well this list of projects on Human Video Generation
-
DeepFaceDrawing: Deep Generation of Face Images from Sketches
-
DeepFaceDrawing Generates Photorealistic Portraits from Freehand Sketches

A team of researchers from the Chinese Academy of Sciences and the City University of Hong Kong has introduced a local-to-global approach that can generate lifelike human portraits from relatively rudimentary sketches.
-
How Baidu’s AI produces news videos using just a URL
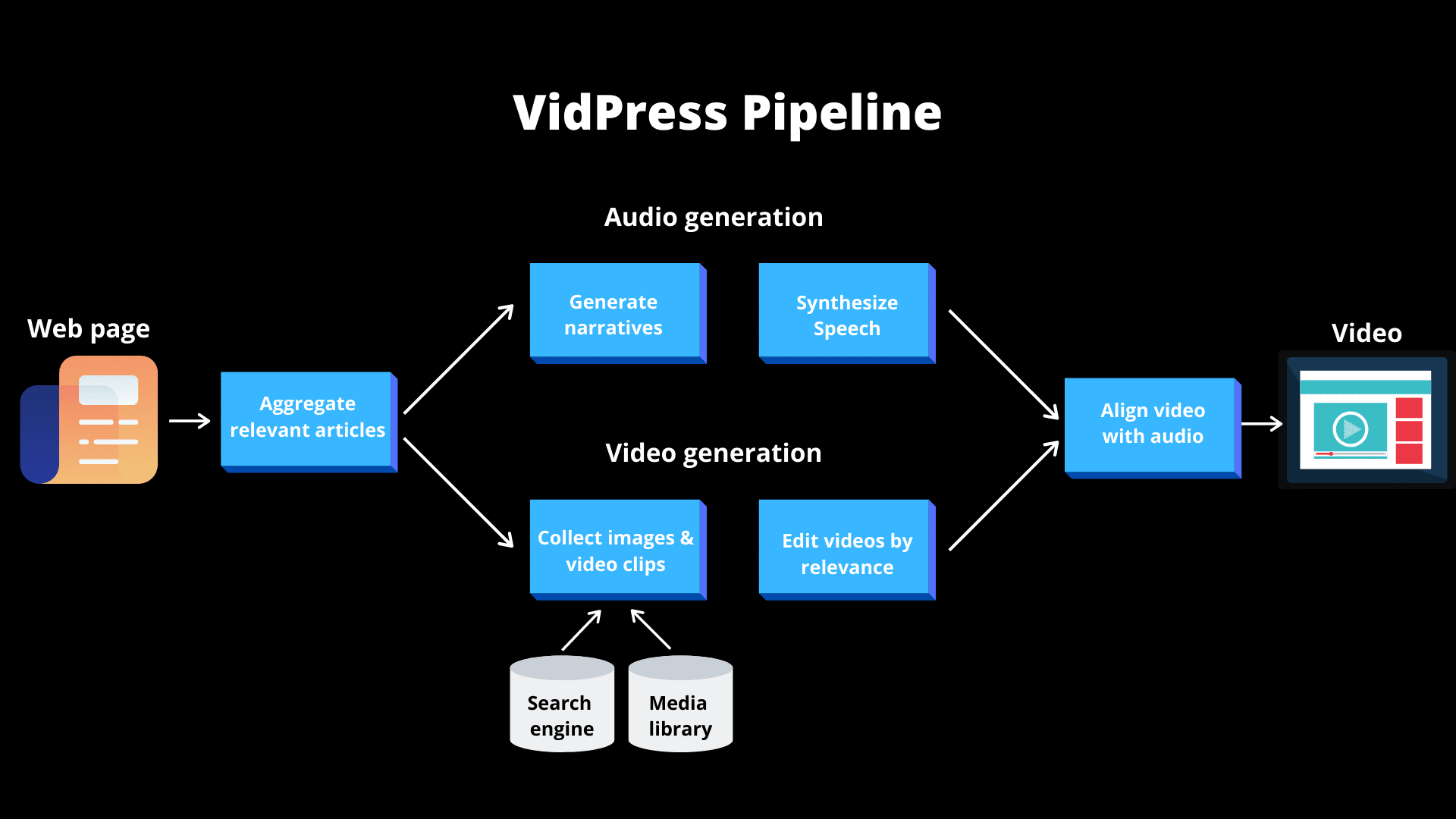
AI for news production is one of the areas that has drawn contrasting opinions. In 2018, an AI anchor developed by China's Xinhua news agency made its debut. Earlier this month, the agency released an improved version that mimics human voices and gestures. There's been advancement in AI with text-based news with algorithms writing great headlines. Baidu has developed a new AI model called Vidpress that brings video and text together by creating a clip based on articles.
-
Chinese state news agency unveils 'the world's first 3D AI anchor' after 'cloning' a human
Xinhua reveals its first AI-powered newsreader using 3D modelling technology. Footage shows the lifelike virtual presenter making her debut in a virtual studio. Developers said they 'cloned' the looks and actions of a journalist at the agency.



-
Queen Elizabeth II reads "Wannabe" by Spice Girls (Speech Synthesis)
-
Milton Friedman reads "P.I.M.P" by 50 Cent (Speech Synthesis)
Notorious B.I.G., Dead Wrong vs. Book of Genesis remix by DJ Jimbo
-
Machine Learning Depth Inpainting of Claude Monet Paintings: Using 3D Photography using Context-aware Layered Depth Inpainting : https://arxiv.org/abs/2004.04727
-
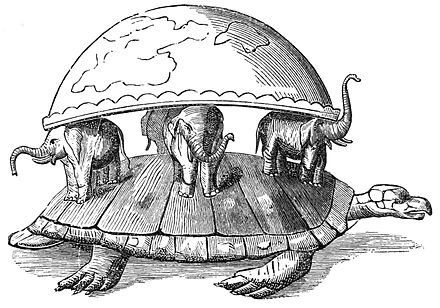
"Turtles all the way down" is an expression of the problem of infinite regress. The saying alludes to the mythological idea of a World Turtle that supports the earth on its back. It suggests that this turtle rests on the back of an even larger turtle, which itself is part of a column of increasingly large world turtles that continues indefinitely (i.e., "turtles all the way down").
-

Within an Anglo-Dutch research collaboration, we discovered that certain types of laser designs output fractal light patterns. This work concerns fractal formation in linear systems, and is quite distinct from our later studies predicting the emergence of spontaneous patterns in nonlinear systems.
Research team demonstrates fractal light from lasers

Reporting this month in Physical Review A, the team provides the first experimental evidence for fractal light from simple lasers and adds a new prediction: that the fractal pattern should exist in 3-D and not just 2-D, as previously thought.
-
Vocal Synthesis Video of "Jay Z" singing Christian Rap Song (Genesis 1:1 Lyrics)
-
ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders
pdf: https://arxiv.org/pdf/2004.11012.pdf abs: https://arxiv.org/abs/2004.11012 audio samples: https://bytesings.github.io/paper1.html
-
OpenAI’s Jukebox Opens the Pandora’s Box of AI-Generated Music (waxy) - OpenAI’s Jukebox AI produces music in any style from scratch — complete with lyrics (venturebeat)
Today, research laboratory OpenAI announced Jukebox, a sophisticated neural network trained on 1.2 million songs with lyrics and metadata, capable of generated original music in the style of various artists and genres, complete with rudimentary singing and vocal mannerisms.
"In this example, the Jukebox AI is fed the lyrics from Eminem’s “Lose Yourself” and told to generate an entirely new song in the style of Kanye West.":
-
ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders (Audio Samples)
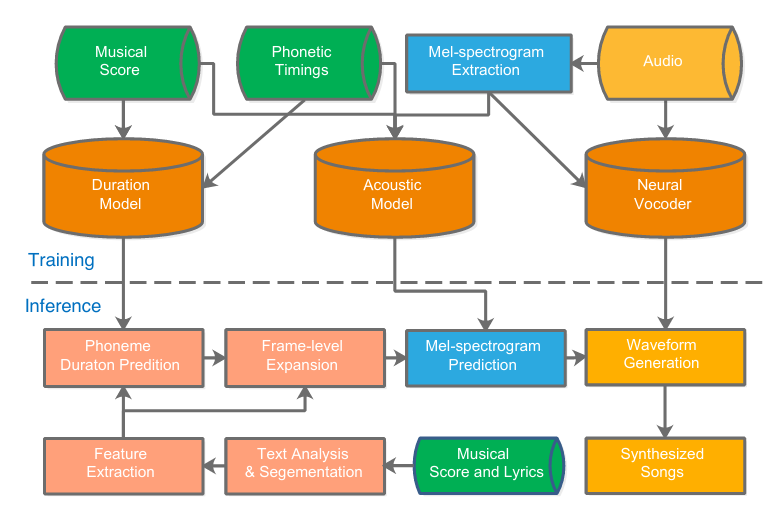
This paper presents ByteSing, a Chinese singing voice synthesis (SVS) system based on duration allocated Tacotron-like acoustic models and WaveRNN neural vocoders. Different fromthe conventional SVS models, the proposed ByteSing employs Tacotron-like encoder-decoder structures as the acoustic models, in which the CBHG models and recurrent neural networks (RNNs) are explored as encoders and decoders respectively.
-
With questionable copyright claim, Jay-Z orders deepfake audio parodies off YouTube

On Friday, I linked to several videos by Vocal Synthesis, a new YouTube channel dedicated to audio deepfakes — AI-generated speech that mimics human voices, synthesized from text by training a state-of-the-art neural network on a large corpus of audio.