tag > Projects
-
OGTAPE 2 – a new mostly AI-generated tune created with @michalho as Count Slobo, our 'AI Music Producer' alias. We pushed the AIs where they're NOT supposed to go, packing 10+ tunes into a 4min footwork-infused experimental banger. Most AI music doesn't sound like this
The levitation music video features mind-bending AI Generated clips by @chorosuke_1019 (link) @masahirochaen (link) @SuguruKun_ai (link) @ai_Tyler_no_bu (link) & few more anons (link)
-
HONGOS - My New Open Source Autonomous AI Video Production Tool
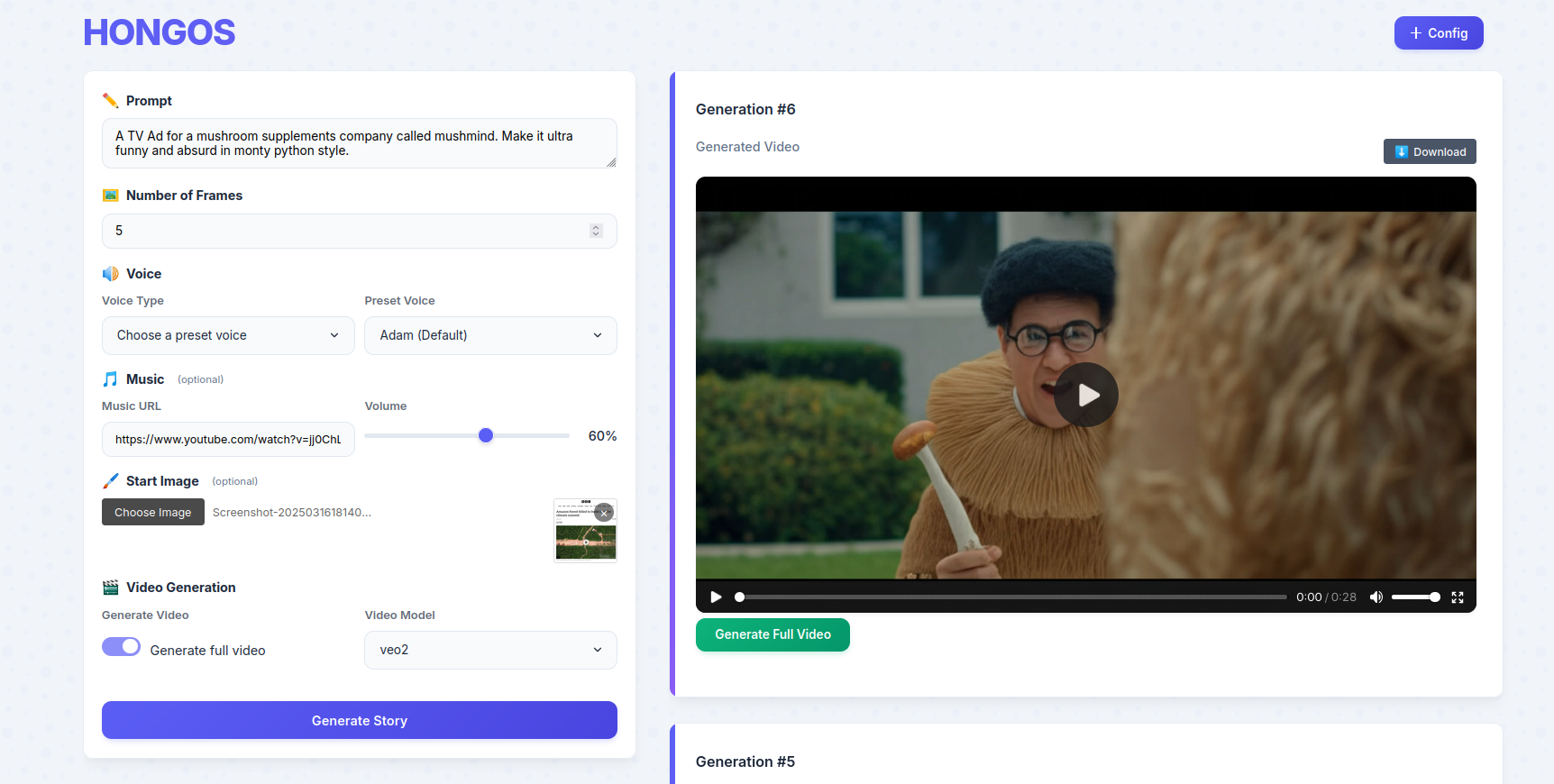
Hongos is my new opensource AI tool that autonomously generates complete videos from a single prompt: Script, Voices, Videos, Edit. From idea to finished video production in minutes
Create ads, stories & viral content in minutes while agencies charge $200K & take 3 months. Hongos opens up an immense, fun creative canvas to play with.
Code: https://github.com/samim23/hongos/
Blog: https://samim.io/studio/work/hongos/ <- Lots of demo videos.It's usable from the command line or through its easy to use interface.
Behind the scenes, HONGOS orchestrates the latest and greatest AI models (@GoogleDeepMind 's Gemini 2.0 Flash & Veo2, Elevenlabsio Voices, LumaLabsAI 's Ray, Fal for compute) and combines it all smartly.
And you can use images to drive the story and video style. Whether it's a familiar face or a specific setting, HONGOS will incorporate it. Do share your results!
At this rate, AI will soon start its own YouTube channel and TV ad agency and make more money than us.
Just had an ad agency CEO, asking me if a 30sec clip would be possible under $1000 and within a week. Told him it's generated in 3min for $10. Last week another ad guy told me "This shouldn't be free." The middleman markup in creative work: genius business or pure scam?
-
The Kiko journey has been fascinating. Some scream, "LLMs for kids' education? Horrible!" Others believe in AI for learning but insist on overcomplicated, gamified UIs to claim a "moat" and "educational value." They all forget—LLMs are improving at breakneck speed and can replicate their entire game UX in minutes. True personalized, real-time learning is coming. And no one is truly ready.
-
I started my first startup at 19 and have built three more since. Through some wins and many failures, I’ve learned just how brutally hard it is to go from 0 to 1.
But the game is changing. AI can now build, clone, and market products in days—handling the entire startup life cycle. What once took countless people can now be done by one. And this shift is only accelerating. Everyone is a coder now. No moat will survive. The traditional startup playbook is being rewritten.
So what comes next? Nobody knows but some signals are clear—these will matter more: community-building, taste-making, performance, and LARPs—all powered by swarms of AI agents running the operations.
Given this shift, what should entrepreneurs focus on right now? Open to ideas!
My current working model is that full-stack AI tools will make 95% of SaaS businesses obsolete within 2-4 years (and later most businesses). What remains will be an AI Agent Marketplace run by tech giants, with former SaaS owners competing for relevance in this new ecosystem.
-
Introducing KIKO – the AI Tutor that made my daughter say "I love learning!". Through natural conversations & interactive AI tools, it personalizes education & turns learning into an adventure—sparking creativity & critical thinking. Read more here....

-
It took me half my life to discover life is a do-it-yourself project. Doing things with the wrong people leads to the wrong outcomes—a harsh mistress of a lesson. It's time to build. Time for DIY.

-
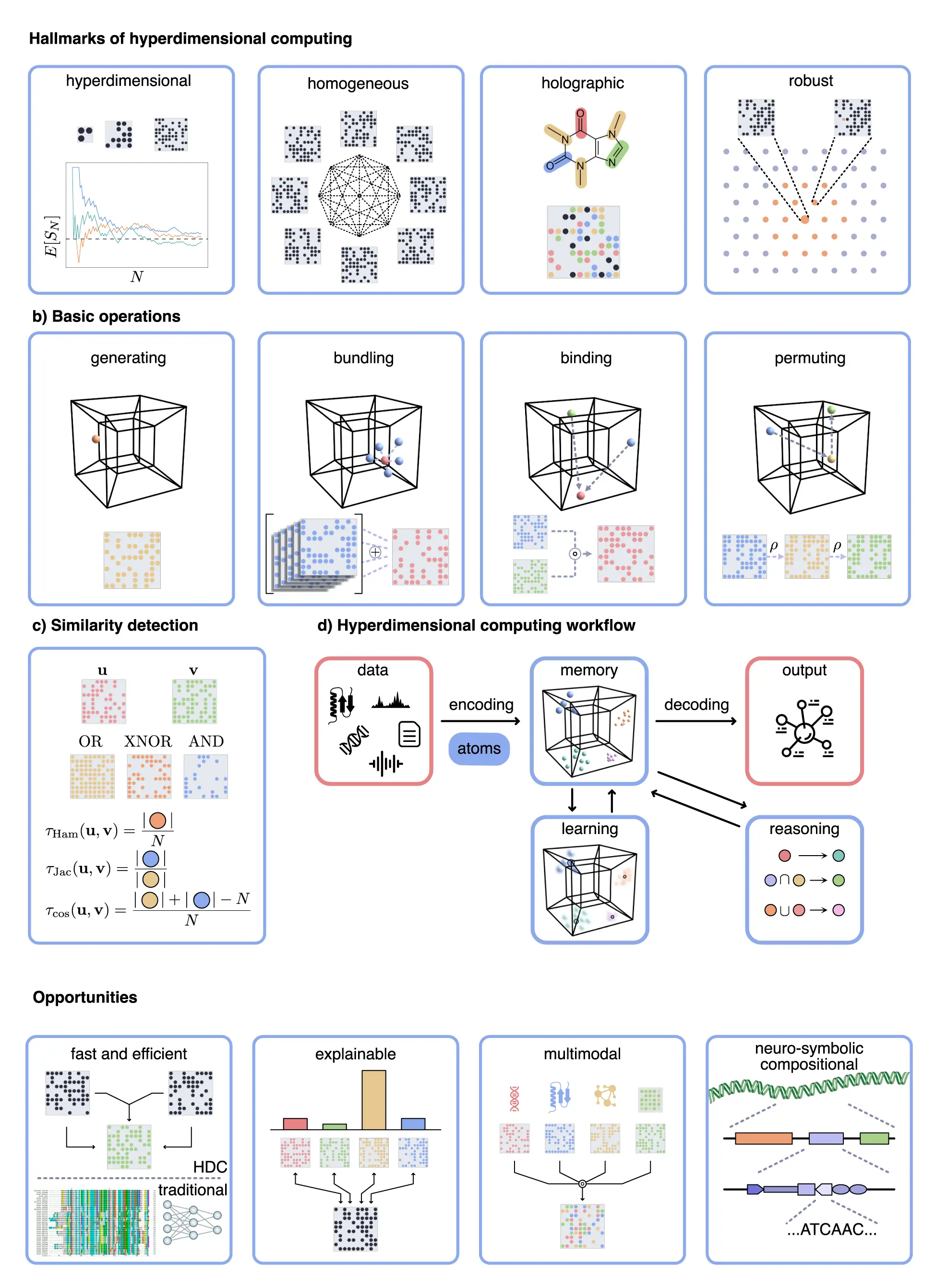
Hyperdimensional Computing (HDC) Playground
Spent a few hours this weekend learning about Hyperdimensional Computing (HDC), inspired by a fun chat with @mwilcox & friends. Built a IPython notebook with toy examples—like an HDC Autoencoder for ImageNet—to learn by tinkering: https://github.com/samim23/hyperdimensional_computing_playground
-
VortexNet: Neural Computing through Fluid Dynamics
Abstract

We present VortexNet, a novel neural network architecture that leverages principles from fluid dynamics to address fundamental challenges in temporal coherence and multi-scale information processing. Drawing inspiration from von Karman vortex streets, coupled oscillator systems, and energy cascades in turbulent flows, our model introduces complex-valued state spaces and phase coupling mechanisms that enable emergent computational properties. By incorporating a modified Navier–Stokes formulation—similar to yet distinct from Physics-Informed Neural Networks (PINNs) and other PDE-based neural frameworks—we implement an implicit form of attention through physical principles. This reframing of neural layers as self-organizing vortex fields naturally addresses issues such as vanishing gradients and long-range dependencies by harnessing vortex interactions and resonant coupling. Initial experiments and theoretical analyses suggest that VortexNet supports integration of information across multiple temporal and spatial scales in a robust and adaptable manner compared to standard deep architectures.
Introduction
Traditional neural networks, despite their success, often struggle with temporal coherence and multi-scale information processing. Transformers and recurrent networks can tackle some of these challenges but might suffer from prohibitive computational complexity or vanishing gradient issues when dealing with long sequences. Drawing inspiration from fluid dynamics phenomena—such as von Karman vortex streets, energy cascades in turbulent flows, and viscous dissipation—we propose VortexNet, a neural architecture that reframes information flow in terms of vortex formation and phase-coupled oscillations.
Our approach builds upon and diverges from existing PDE-based neural frameworks, including PINNs (Physics-Informed Neural Networks), Neural ODEs, and more recent Neural Operators (e.g., Fourier Neural Operator). While many of these works aim to learn solutions to PDEs given physical constraints, VortexNet internalizes PDE dynamics to drive multi-scale feature propagation within a neural network context. It is also conceptually related to oscillator-based and reservoir-computing paradigms—where dynamical systems are leveraged for complex spatiotemporal processing—but introduces a core emphasis on vortex interactions and implicit attention fields.
Interestingly, this echoes the early example of the MONIAC and earlier analog computers that harnessed fluid-inspired mechanisms. Similarly, recent innovations like microfluidic chips and neural networks highlight how physical systems can inspire new computational paradigms. While fundamentally different in its goals, VortexNet demonstrates how physical analogies can continue to inform and enrich modern computation architectures.
Core Contributions:
- PDE-based Vortex Layers: We introduce a modified Navier–Stokes formulation into the network, allowing vortex-like dynamics and oscillatory phase coupling to emerge in a complex-valued state space.
- Resonant Coupling and Dimensional Analysis: We define a novel Strouhal-Neural number (Sn), building an analogy to fluid dynamics to facilitate the tuning of oscillatory frequencies and coupling strengths in the network.
- Adaptive Damping Mechanism: A homeostatic damping term, inspired by local Lyapunov exponent spectrums, stabilizes training and prevents both catastrophic dissipation and explosive growth of activations.
- Implicit Attention via Vortex Interactions: The rotational coupling within the network yields implicit attention fields, reducing some of the computational overhead of explicit pairwise attention while still capturing global dependencies.
Core Mechanisms
-
Vortex Layers:
The network comprises interleaved “vortex layers” that generate counter-rotating activation fields. Each layer operates on a complex-valued state space
S(z,t), wherezrepresents the layer depth andtthe temporal dimension. Inspired by, yet distinct from PINNs, we incorporate a modified Navier–Stokes formulation for the evolution of the activation:∂S/∂t = ν∇²S - (S·∇)S + F(x)Here,
νis a learnable viscosity parameter, andF(x)represents input forcing. Importantly, the PDE perspective is not merely for enforcing physical constraints but for orchestrating oscillatory and vortex-based dynamics in the hidden layers. -
Resonant Coupling:
A hierarchical resonance mechanism is introduced via the dimensionless Strouhal-Neural number (Sn):
Sn = (f·D)/A = φ(ω,λ)In fluid dynamics, the Strouhal number is central to describing vortex shedding phenomena. We reinterpret these variables in a neural context:
- f is the characteristic frequency of activation
- D is the effective layer depth or spatial extent (analogous to domain or channel dimension)
- A is the activation amplitude
- φ(ω,λ) is a complex-valued coupling function capturing phase and frequency shifts
- ω represents intrinsic frequencies of each layer
- λ represents learnable coupling strengths
By tuning these parameters, one can manage how quickly and strongly oscillations propagate through the network. The Strouhal-Neural number thus serves as a guiding metric for emergent rhythmic activity and multi-scale coordination across layers.
-
Adaptive Damping:
We implement a novel homeostatic damping mechanism based on the local Lyapunov exponent spectrum, preventing both excessive dissipation and unstable amplification of activations. The damping is applied as:
γ(t) = α·tanh(β·||∇L||) + γ₀Here,
||∇L||is the magnitude of the gradient of the loss function with respect to the vortex layer outputs,αandβare hyperparameters controlling the nonlinearity of the damping function, andγ₀is a baseline damping offset. This dynamic damping helps keep the network in a regime where oscillations are neither trivial nor diverging, aligning with the stable/chaotic transition observed in many physical systems.
Key Innovations
- Information propagates through phase-coupled oscillatory modes rather than purely feed-forward paths.
- The architecture supports both local and non-local interactions via vortex dynamics and resonant coupling.
- Gradient flow is enhanced through resonant pathways, mitigating vanishing/exploding gradients often seen in deep networks.
- The system exhibits emergent attractor dynamics useful for temporal sequence processing.
Expanded Numerical and Implementation Details
To integrate the modified Navier–Stokes equation into a neural pipeline, VortexNet discretizes
S(z,t)over time steps and spatial/channel dimensions. A lightweight PDE solver is unrolled within the computational graph:-
Discretization Strategy: We employ finite differences or
pseudo-spectral methods depending on the dimensionality of
S. For 1D or 2D tasks, finite differences with periodic or reflective boundary conditions can be used to approximate spatial derivatives. - Boundary Conditions: If the data is naturally cyclical (e.g., sequential data with recurrent structure), periodic boundary conditions may be appropriate. Otherwise, reflective or zero-padding methods can be adopted.
-
Computational Complexity: Each vortex layer scales
primarily with
O(T · M)orO(T · M log M), whereTis the unrolled time dimension andMis the spatial/channel resolution. This can sometimes be more efficient than explicitO(n²)attention when sequences grow large. -
Solver Stability: To ensure stable unrolling, we maintain a
suitable time-step size and rely on the adaptive damping mechanism.
If
νorfare large, the network will learn to self-regulate amplitude growth viaγ(t). - Integration with Autograd: Modern frameworks (e.g., PyTorch, JAX) allow automatic differentiation through PDE solvers. We differentiate the discrete update rules of the PDE at each layer/time step, accumulating gradients from output to input forces, effectively capturing vortex interactions in backpropagation.
Relationship to Attention Mechanisms
While traditional attention mechanisms in neural networks rely on explicit computation of similarity scores between elements, VortexNet’s vortex dynamics offer an implicit form of attention grounded in physical principles. This reimagining yields parallels and distinctions from standard attention layers.
1. Physical vs. Computational Attention
In standard attention, weights are computed via:
A(Q,K,V) = softmax(QK^T / √d) VIn contrast, VortexNet’s attention emerges via vortex interactions within
S(z,t):A_vortex(S) = ∇ × (S·∇)SWhen two vortices come into proximity, they influence each other’s trajectories through the coupled terms in the Navier–Stokes equation. This physically motivated attention requires no explicit pairwise comparison; rotational fields drive the emergent “focus” effect.
2. Multi-Head Analogy
Transformers typically employ multi-head attention, where each head extracts different relational patterns. Analogously, VortexNet’s counter-rotating vortex pairs create multiple channels of information flow, with each pair focusing on different frequency components of the input, guided by their Strouhal-Neural numbers.
3. Global-Local Integration
Whereas transformer-style attention has
O(n²)complexity for sequence lengthn, VortexNet integrates interactions through:- Local interactions via the viscosity term
ν∇²S - Medium-range interactions through vortex street formation
- Global interactions via resonant coupling
φ(ω, λ)
These multi-scale interactions can reduce computational overhead, as they are driven by PDE-based operators rather than explicit pairwise calculations.
4. Dynamic Memory
The meta-stable states supported by vortex dynamics serve as continuous memory, analogous to key-value stores in standard attention architectures. However, rather than explicitly storing data, the network’s memory is governed by evolving vortex fields, capturing time-varying context in a continuous dynamical system.
Elaborating on Theoretical Underpinnings
Dimensionless analysis and chaotic dynamics provide a valuable lens for understanding VortexNet’s behavior:
- Dimensionless Groups: In fluid mechanics, groups like the Strouhal number (Sn) and Reynolds number clarify how different forces scale relative to each other. By importing this idea, we condense multiple hyperparameters (frequency, amplitude, spatial extent) into a single ratio (Sn), enabling systematic tuning of oscillatory modes in the network.
-
Chaos and Lyapunov Exponents: The local Lyapunov exponent
measures the exponential rate of divergence or convergence of trajectories
in dynamical systems. By integrating
||∇L||into our adaptive damping, we effectively constrain the system at the “edge of chaos,” balancing expressivity (rich oscillations) with stability (bounded gradients). - Analogy to Neural Operators: Similar to how Neural Operators (e.g., Fourier Neural Operators) learn mappings between function spaces, VortexNet uses PDE-like updates to enforce spatiotemporal interactions. However, instead of focusing on approximate PDE solutions, we harness PDE dynamics to guide emergent vortex structures for multi-scale feature propagation.
Theoretical Advantages
- Superior handling of multi-scale temporal dependencies through coupled oscillator dynamics
- Implicit attention and potentially reduced complexity from vortex interactions
- Improved gradient flow through resonant coupling, enhancing deep network trainability
- Inherent capacity for meta-stability, supporting multi-stable computational states
Reframing neural computation in terms of self-organizing fluid dynamic systems allows VortexNet to leverage well-studied PDE behaviors (e.g., vortex shedding, damping, boundary layers), which aligns with but goes beyond typical PDE-based or physics-informed approaches.
Future Work
-
Implementation Strategies:
Further development of efficient PDE solvers for the modified Navier–Stokes
equations, with an emphasis on numerical stability,
O(n)orO(n log n)scaling methods, and hardware acceleration (e.g., GPU or TPU). Open-sourcing such solvers could catalyze broader exploration of vortex-based networks. -
Empirical Validation:
Comprehensive evaluation on tasks such as:
- Long-range sequence prediction (language modeling, music generation)
- Multi-scale time series analysis (financial data, physiological signals)
- Dynamic system and chaotic flow prediction (e.g., weather or turbulence modeling)
- Architectural Extensions: Investigating hybrid architectures that combine VortexNet with convolutional, transformer, or recurrent modules to benefit from complementary inductive biases. This might include a PDE-driven recurrent backbone with a learned attention or gating mechanism on top.
- Theoretical Development: Deeper mathematical analysis of vortex stability and resonance conditions. Establishing stronger ties to existing PDE theory could further clarify how emergent oscillatory modes translate into effective computational mechanisms. Formal proofs of convergence or stability would also be highly beneficial.
-
Speculative Extensions: Fractal Dynamics, Scale-Free Properties, and Holographic Memory
-
Fractal and Scale-Free Dynamics: One might incorporate wavelet or multiresolution expansions in the PDE solver to natively capture fractal structures and scale-invariance in the data. A more refined “edge-of-chaos” approach could dynamically tune
νandλusing local Lyapunov exponents, ensuring that VortexNet remains near a critical regime for maximal expressivity. - Holographic Reduced Representations (HRR): By leveraging the complex-valued nature of VortexNet’s states, holographic memory principles (e.g., superposition and convolution-like binding) could transform vortex interactions into interference-based retrieval and storage. This might offer a more biologically inspired alternative to explicit key-value attention mechanisms.
-
Fractal and Scale-Free Dynamics: One might incorporate wavelet or multiresolution expansions in the PDE solver to natively capture fractal structures and scale-invariance in the data. A more refined “edge-of-chaos” approach could dynamically tune
Conclusion
We have introduced VortexNet, a neural architecture grounded in fluid dynamics, emphasizing vortex interactions and oscillatory phase coupling to address challenges in multi-scale and long-range information processing. By bridging concepts from partial differential equations, dimensionless analysis, and adaptive damping, VortexNet provides a unique avenue for implicit attention, improved gradient flow, and emergent attractor dynamics. While initial experiments are promising, future investigations and detailed theoretical analyses will further clarify the potential of vortex-based neural computation. We believe this fluid-dynamics-inspired approach can open new frontiers in both fundamental deep learning research and practical high-dimensional sequence modeling.
Code
This repository contains toy implementations of some of the concepts introduced in this research.



-
With LLMs making app development dramatically easier, I’ve started creating bespoke mini apps for my 5-year-old daughter as a hobby. It’s incredibly rewarding—especially since few seem to be exploring how AI can uniquely serve this age group.















-
Flow: A lightweight static site generator with built-in UI editor that creates microblog-style content feeds. Ideal for personal blogs

Blogging remains one of the most powerful practices for developing ideas, sharing knowledge, and connecting with others. Writing regularly has helped me clarify my thinking, document my learning, and engage with fascinating people around the world.
But while there are many blogging platforms available, I found they didn't quite fit my needs. WordPress feels too heavy and complex. Medium lacks ownership and customization. Static site generators require too much configuration. And social media platforms optimize for engagement rather than thoughtful content.
I wanted something different: A lightweight solution that makes publishing frictionless, focuses on readability, and encourages a steady stream of ideas - from quick thoughts to longer essays. A tool that helps maintain a digital garden of knowledge that grows over time.
That's why I built Flow - a static blogging engine with a built-in editor that gets out of your way and lets you focus on what matters: writing and sharing ideas. No complex dashboards, no endless configuration, no optimization for algorithms. Just clean, simple publishing.
Flow is Open Source and Free: https://github.com/samim23/flow
Features:
- ⚡ Super fast site generation, built with Python/FastAPI
- 📝 Easy WYSIWYG UI editing experience
- 🏷️ Supports tagging and content exploration
- 📡 One-click publishing to your server
- ✨ Minimal configuration
-
ULTRA SIGMA: SLOBODAN does not care. Only DANCE. This is NOT music. This is ENERGY.
-
442 Weeks ago, in 2016, Samim Winiger was talking about Creative Artificial Intelligence at IAMW16

-
Soft-Wireheading Simulacrum has been achieved internally
-
XCheck
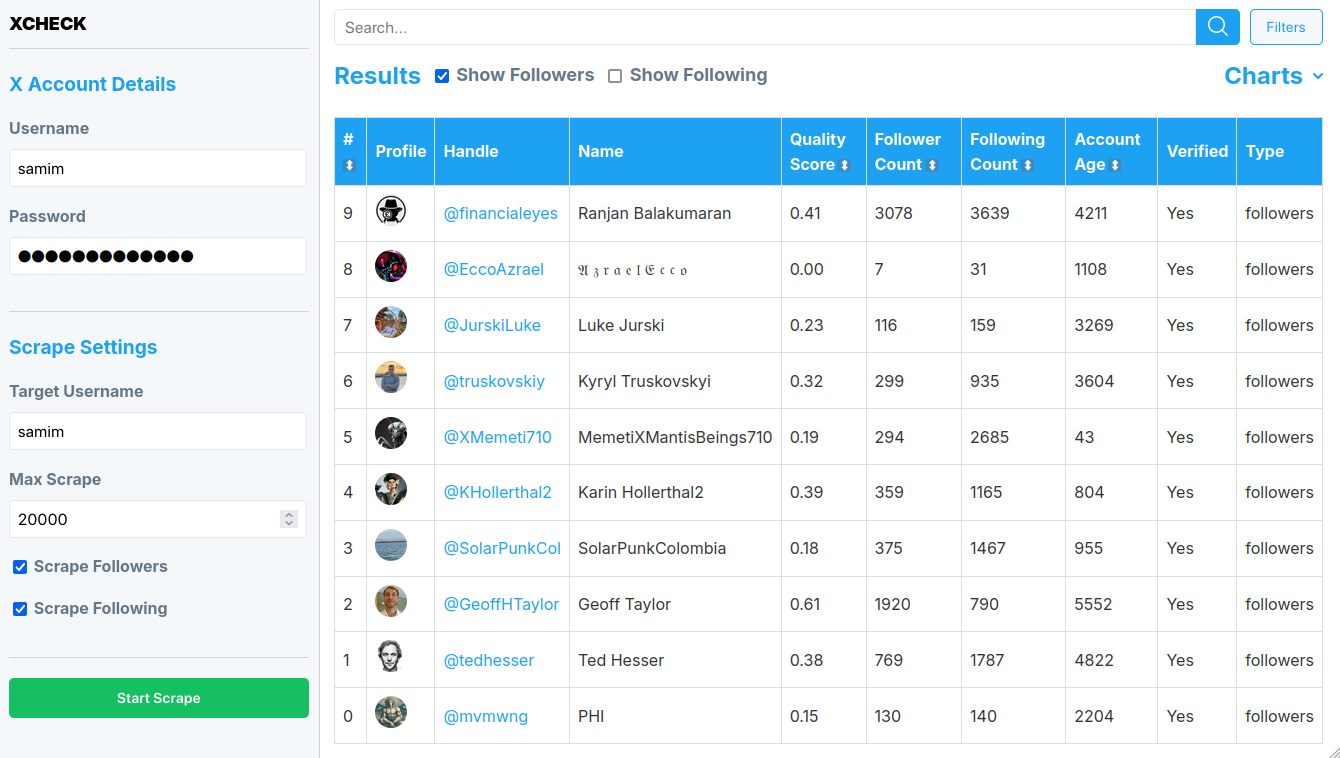
I thought I was doing well on X with 20K followers. Turns out, I was mostly talking to ghosts and bots that have invaded X but are hard to detect. That's why I built XCheck, a personal X detective that analyzes your network.
Backstory: X/Twitter user since 2007, gradually built a network. Recently noticed odd plummeting engagement. Manual analysis revealed a suspicion: inactive accounts and bots were significantly impacting my reach. Digging into other accounts, I discovered this wasn't isolated - it's a widespread X phenomenon.
Enter XCheck: A little open-source tool that crawls and analyzes your X account (or any other's) and uncovers hidden patterns in your social network.
XCheck's key features:
- Intuitive, interactive web UI for X crawling
- Analyzes followers/following of any public X account
- Auto-assigns quality scores to accounts
- Filtering, search and visualization tools
XCheck is free and open-source: https://github.com/samim23/xcheck
-
Decades ago, my dear friend @michalho and I began producing music as teens. We've since released many songs, EPs, played countless gigs, and- had a great time in the scene. Today, I'm thrilled to announce we've finally dropped our first album. Give it a listen!

-
I ported "InternLM-XComposer-2.5 - A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output" by @wjqdev et al - to @replicate. It excels in various img-2-text tasks, achieving GPT-4V level capabilities with just a 7B LLM backend
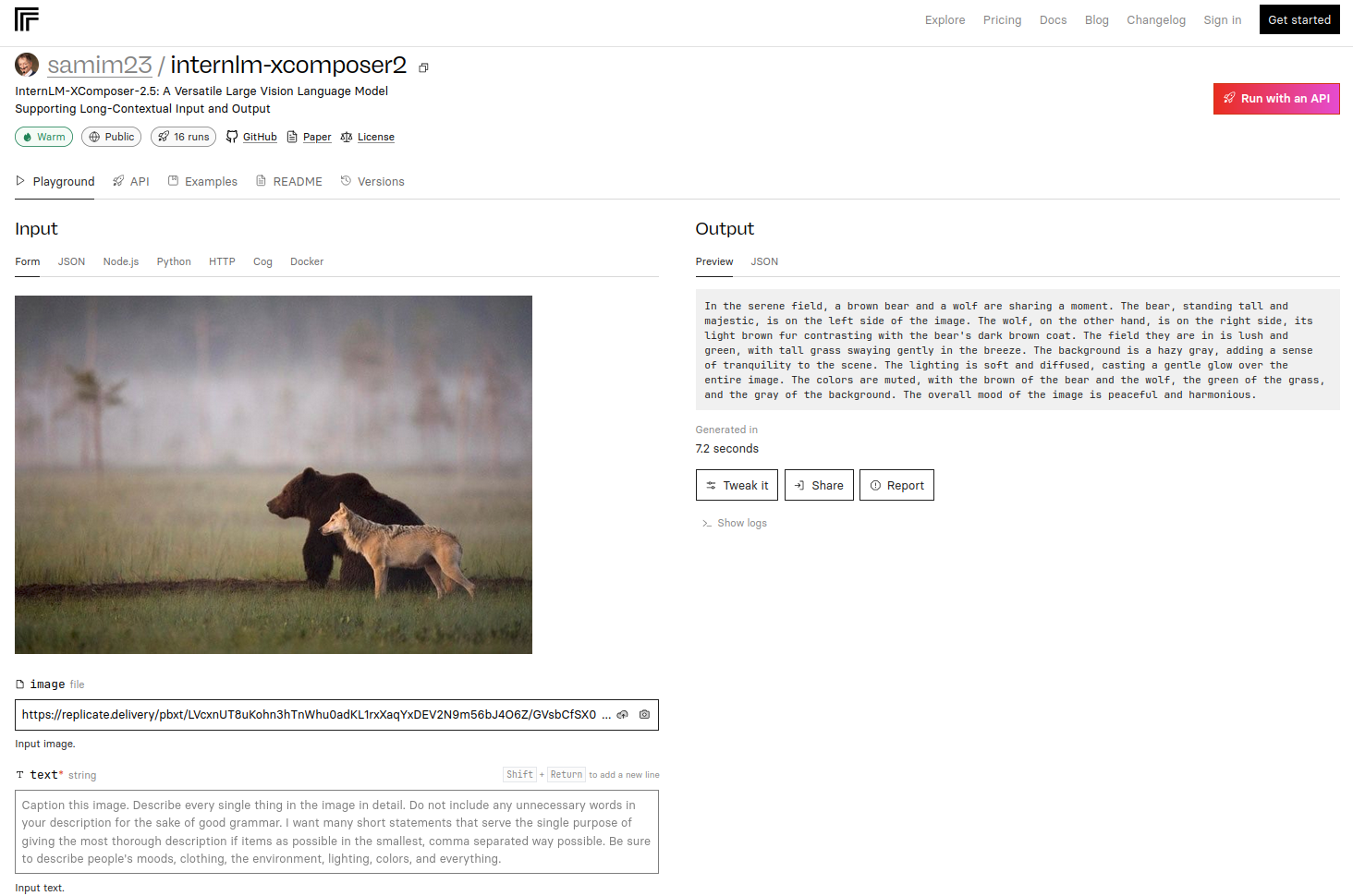
-
It's the early 2000s in Berlin. It's time for for Music by Samim & MIchal on Freizeitglauben. Exercise EP feat. the classic PG32. Good times. After all these years, this summer S&M releases it's first LP.