tag > Comment
-
The Machine in the Ghost
Antwerp is the cocaine capital of Europe. A senior offical recently said that Belgium is drifting toward becoming a narco-state. And Antwerp is the most scrutinized port in Europe. The seizures break records every year. Why are both facts getting stronger at the same time?
The state runs a top-down stack — scanners, satellites, databases, compliance regimes, digital currencies. The networks it hunts run a different stack entirely: older, wetter, and lower to the ground. When the two collide, the shadow stack wins so consistently that you have to stop calling it cheating. It’s better architecture.
The asymmetry starts at the power source. The state’s machine runs on budgets — money extracted, appropriated, fought over in committee, and spent down. Enforcement is a cost center, and cost centers are always scarce. The shadow’s machine runs on the exact inverse: it doesn’t spend to fight, it gets paid to. Its fuel is human desire. Every seizure thins the supply, lifts the price, and hands the survivors a fatter margin; a kilo bought for a few thousand euros at origin clears the port worth thirty. Repression isn’t friction on this engine. It’s fuel. The drug war is a subsidy to the efficient — the state paying to make the problem more profitable.
The shadow wins by refusing to fight on the state’s terrain. Antwerp installs scanners worth millions; the smugglers drop GPS-tagged waterproof bundles into the North Sea for a fishing boat to collect. Compliance regimes map every transaction; the money moves by mirror swap instead — cash handed to a broker in Antwerp, yuan deposited in Shenzhen, clean pesos released in Medellín, three continents settled and nothing ever touched SWIFT. Every layer of control creates its own bypass, and the pressure of the control sets the strength of the bypass.
The threat is not inside the system, the threat is the system, wearing it like a suit. China is the proof at civilizational scale. No actor on Earth has built the state stack more completely — cash abolished into a fully identity-verified digital yuan, ports so automated that human hands never touch a container. And yet, that same state is backbone of the global shadow economy. The tightest grip in the world produces the strongest phantom layer in the world.
The cash doesn’t stay in the underworld. It rises to the top as the most respectable substance on Earth. When the 2008 crisis froze interbank lending, the head of the UN Office on Drugs and Crime stated flatly that drug money was some of the only liquid investment capital in the system — that hundreds of billions in narco-profits flowed into banks that would otherwise have failed. The shadow didn’t attack the temple. The shadow recapitalized it.
This entire lineage ancient. The East India Company ran the largest drug cartel in human history under a royal charter, with the Royal Navy as its enforcement arm; when China objected, Britain went to war twice for the right to keep trafficking. HSBC was born in that Hong Kong — and a century and a half later the same bank paid what was then the largest money-laundering settlement in history for washing Sinaloa cartel cash. This generation’s smuggler is the next generation’s endowment. Power has always metabolized its shadow, and the digestion is the oldest institution we have.
Prohibition is the price floor. The margin exists only because the law creates it. The margin flows upward and becomes establishment capital. The establishment writes the laws. The laws preserve the margin. Nobody needs to plan this — every actor follows their local incentive, and the loop assembles itself, generation after generation, behaving exactly as if it were designed.
The counterfactual proves it. Legalize, and the margin collapses from fifty thousand euros a kilo to the production cost of coffee — the entire shadow economy bankrupted overnight. It is the one intervention that would actually work, and it is the one experiment the system never runs. Draw your own conclusion about who is protecting the margin.
The state’s stack assumes the machine wins and humans are bugs inside it. The shadow stack is the proof that the bugs run the show — that any system built of laws, sensors, and databases will be hacked, bent, and re-routed by desire, trust, and geography.
But “shadow” is the machine’s word for it, and it has the picture backwards. Hawala predates the bank by a thousand years. Smuggling predates the customs house. Trust predates the state. Desire, trust, and geography aren’t a deviation from the system — they are the substrate the system was briefly painted onto. The top-down machine is the recent experiment. The ghost is the incumbent.
#Politics #Comment #Economics #Technology #Culture #Cryptocracy #fnord
-
Physics, not simulation. Or why physics-informed neural networks, such as ONN's, do not work well on digital GPU's.
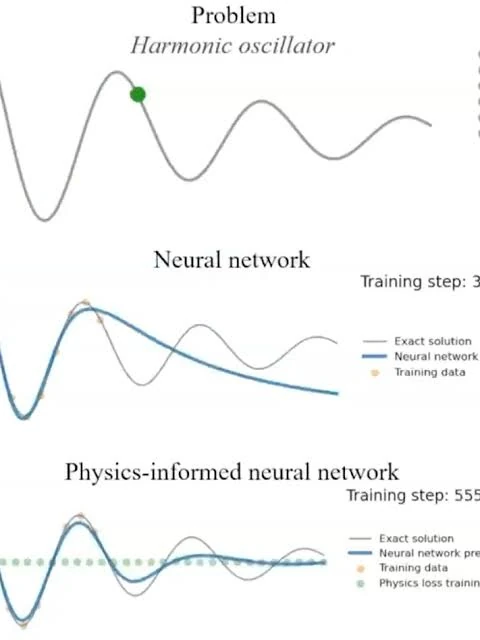
The success of current machine learning models are determined almost entirely by the training objective and scale, not by the dynamics engine. Chasing parity with alternative architectures - like oscillatory neural networks - at any scale is a category error. But the bigger picture is important: Nature doesn't backprop through a Kuramoto model on an A100 — it is the oscillators. A coupled-oscillator network settling to phase-lock is solving an optimization by physically rolling downhill, in continuous time, at the speed of the substrate, burning near-zero energy. That's the entire pitch of analog/neuromorphic oscillator hardware: Ising machines, coupled spin-torque or ring oscillators solving combinatorial problems, phase-based associative memory in silicon. The win is femtojoules and nanoseconds. When you run the same dynamics on a GPU you pay full digital cost and keep none of the physical advantage - you're paying to emulate the thing whose only edge was not needing to be emulated.
Related: Peking University and CAS Develop World's First Neurodynamic Chip Based on Phase-Change Memristors
-
120 years of cinema, 5,000 years of science, and the birth of super-intelligent AI...Only for us to scroll past art to watch brain-rotting slop that targets our oldest evolutionary instincts. As E.O. Wilson said: “We have created a Star Wars civilization, with Stone Age emotions.”
“To slop, or not to slop, that is the question” - William Slopspeare
-
"Magic isn’t randomness. Magic is meaningful coincidence."
I need a "networked, real-time, lightweight synchronicity engine" that helps to "self-generated synchronicity" through a "system that perturbs your path through reality just enough to create meaning" to "amplify perception of anomalies through synchronized attention"
-
Agentic software engineering best practices
We are entering a phase where most of the code in a system is no longer written by humans.
AI agents generate the majority of implementation. Humans review, guide, and intervene at critical points.
This shifts the core question of software engineering from:
"How do we write correct code?"
to:
"How do we ensure the system cannot easily become incorrect?"
Because AI-generated code has a very specific failure mode: it often looks locally correct, while being globally inconsistent.
A single agent can produce 500 lines of clean, plausible, well-structured code that silently contradicts what another agent wrote last week.
Neither agent was wrong in isolation.
The system was wrong in aggregate.And that is only the code-generation problem. In agentic systems, AI is no longer just generating code — it is making decisions: what to call, when to act, how to sequence operations, often without a human in the loop per action. The discipline of constraining a code generator is different from the discipline of governing an autonomous agent. Both problems are now yours.
The response from the best teams is not “more code review.”
It is a fundamentally different engineering discipline.
The Core Shift: From Code Quality → System Truth
In AI-driven codebases, correctness does not primarily come from:
- clean abstractions
- elegant code
- high test coverage
It comes from forcing the system to obey a small set of explicit truths.
These truths must be:
- defined before implementation begins
- enforced across all layers
- testable, observable, and explainable
The quality bar for critical systems should not be framed as “good test coverage.”
Prove the system cannot easily lie, race, double-apply, drift, or mis-explain itself.
That means the bar includes all of:
- correctness
- auditability
- explainability
- replay safety
- migration safety
- non-destructive enforcement
- honest UX
Each of those is a separate thing to design for, not a side effect of passing tests.
The following practices define what must happen before a line of code is generated.
1. Write the Spec Before the Code
This is the most counterintuitive shift for teams moving fast with AI.
The instinct is to generate code quickly and iterate.
The problem is that AI will improvise the contract if you don’t give it one.Before large implementation begins, write down:
- invariants: rules the system must never violate
- state transitions: what states exist, what moves between them
- ownership boundaries: who owns which truth, who may not
- failure behavior: what happens when things go wrong
- event schemas: what events exist, what they mean
This does not need to be a long document.
It needs to be a compact, precise domain contract that both humans and AI implementations are measured against.Apply the same discipline to individual agent tasks. Every task handed to an agent should specify four things:
- Scope: what is explicitly in and out of bounds
- Output format: exactly what the result must look like
- Done-when: the observable condition that marks completion
- Success criteria: how a human will evaluate correctness
These constraints prevent the most common agent task failures: mid-task clarification loops, wildly inconsistent outputs across runs, and agents continuing past the point where they should have stopped. A well-constrained agent fails faster when something is wrong — which is a feature, not a limitation.
Without it, you are not directing AI.
You are hoping it converges.
2. Define Invariants — and Make Them Machine-Checkable
Before writing or generating code, define a small set of invariants: rules that must never be violated, regardless of code path, feature, or edge case.
But write them precisely enough to be checked mechanically, not just read and interpreted.
Natural language invariants are still ambiguous. “Concurrent operations must not corrupt shared state” is not an invariant — it is a hope. A real invariant is a predicate over the state space that a machine can evaluate. If your invariant cannot be expressed in code or a formal notation, it is probably not precise enough.
Examples (generalized):
- value cannot be created or destroyed implicitly
- state transitions must follow defined rules
- duplicate external events must not double-apply
- concurrent operations must not corrupt shared state
- derived views must always reconcile back to source data
These invariants become:
- test anchors
- review criteria
- migration checks
- runtime assertions
- debugging tools
Also distinguish two fundamentally different classes:
- Safety properties: nothing bad ever happens (no double-grant, no corrupt state, no data loss)
- Liveness properties: something good eventually happens (events are eventually processed, blocked states eventually resolve, workflows eventually complete)
Most teams only test safety. Liveness failures are equally dangerous in agentic systems — an agent that never completes, an event that is never processed, a stuck workflow with no resolution path.
Go further with property-based testing. Don’t only write scenario tests — write generators that explore random inputs against your invariants automatically. Tools like Hypothesis, fast-check, or QuickCheck will find cases your hand-written tests never imagined. This is especially powerful for concurrency: generate random interleavings of operations and verify that invariants hold across all of them.
Go further still with model checking. Property-based testing is probabilistic — it samples from the state space. Model checking is exhaustive — it explores every reachable state and proves the property holds across all of them, not just a large random sample. Tools like TLA+ and Alloy let you write a formal model of your system and verify critical invariants before writing any implementation code. For the highest-risk invariants — those where a single missed case causes irreversible harm — probabilistic sampling is not the right bar. You want a proof.
One concrete data point on why this matters: current best models achieve around 73% code correctness on formal benchmarks but only 4.9% proof success. The gap between generating plausible code and being able to formally verify that code is enormous. AI cannot close this gap on its own. The verification is yours to own.
Embed invariants in the running system, not just the test suite. If an invariant is important enough to specify, it is important enough to check continuously in production. Runtime verification means the live system checks critical predicates on every relevant operation and surfaces violations immediately — not in the next test run or the next deploy. This is your last line of defense against invariant drift in production.
Without invariants, AI systems drift.
Without machine-checkable invariants, drift goes undetected.
Without runtime verification, drift in production goes undetected until it causes harm.
3. Red-Team Your Spec Before Writing Any Code
Here is a failure mode the post’s framing so far does not address: specification gaming.
AI systems are optimizers. They optimize for the letter of what you specified. Your invariants define what must not be violated — and AI will generate code that technically satisfies your invariants while violating their intent in ways you did not anticipate. This is not a theoretical concern. It is how these systems behave.
A well-written spec is necessary but not sufficient. You must also attack it.
Before implementation begins:
- Write negative constraints alongside your invariants: not just what must be true, but what must never happen even if all invariants are satisfied
- Attempt to construct scenarios that satisfy all your stated invariants while clearly behaving wrongly
- Where you succeed, your spec has a gap — close it before code is generated against it
- Treat the spec as a surface to be attacked, not a document to be trusted
The goal is to find the gaps in your own specification before the AI finds them implicitly.
With spec and invariants established, these practices define how the system itself must be structured.
4. Separate the Truth Layer from the Representation Layer
One of the biggest risks in AI-generated systems is hidden state divergence.
Strong systems separate:
- Truth layer: append-only events or canonical state
- Projection layer: derived, queryable views
This allows you to:
- reconstruct any state
- audit changes
- replay behavior
- detect inconsistencies
AI is very good at generating projections.
It is much worse at maintaining consistent truth.So you constrain it. Give AI the projection layer. Own the truth layer yourself.
5. Eliminate Hidden Coupling Aggressively
AI-generated code is especially prone to:
- duplicate logic across surfaces
- near-miss semantics that subtly disagree
- accidental shadow state
- different parts of the system saying slightly different things
The antidote is deliberate singularity:
- one source of truth
- one enforcement path
- one projection layer
- one way to represent each concept
When you let AI improvise these boundaries, you get systems that are locally tidy but globally incoherent.
When you define them explicitly, AI fills in the implementation without corrupting the structure.Coupling is where AI-generated codebases quietly rot.
6. Design for Replay, Idempotency, and Duplication
In distributed systems, especially those interacting with external APIs:
- events can arrive twice
- events can arrive late
- events can arrive out of order
AI-generated code often assumes happy paths.
Robust systems assume chaos.
Key principles:
- all external inputs must be idempotent
- replay must not change outcomes
- duplicate processing must be safe
- ordering assumptions must be minimal
If your system cannot safely replay history, it cannot be trusted. This is a design property, not a testing property — it must be built in from the start.
7. Treat Concurrency as a First-Class Problem
AI-generated code frequently fails under:
- race conditions
- simultaneous updates
- shared resource contention
So you explicitly design for:
- atomic operations
- consistent locking or transactional boundaries
- protection against double-spend / double-write
- safe behavior at boundary conditions (zero, limits, exhaustion)
Concurrency bugs are where “looks correct” systems break — and where AI-generated code is most likely to have assumed the happy path without realizing it.
8. Rehearse Migrations, Don’t Assume Them
In AI-heavy systems, migrations are especially dangerous because:
- logic is often duplicated
- assumptions are implicit
- edge cases are missed
Best practice:
- define deterministic migration rules
- run migrations on real or representative data
- verify invariants after migration
- define rollback or forward-fix strategy
Migration is not a step.
It is a system test.
Good structure is necessary but not sufficient. These practices define how to validate that the system actually behaves correctly.
9. Test Scenarios, Not Just Functions
AI-generated systems often pass unit tests but fail real-world workflows.
So you must test scenarios, not just components.
A useful test pyramid for AI-heavy systems:
- unit tests: individual functions, rules, projections
- integration tests: multi-component flows, external event handling, state transitions
- scenario tests: full lifecycle journeys, boundary conditions, failure and recovery paths
- property-based tests: generated random inputs checked against invariants, especially for concurrency
- manual checks: production-like end-to-end verification, UI walkthroughs, post-migration sanity
The key question at every level:
Does the system behave coherently over time, not just in isolation?
A note on AI-powered testing itself. Historically, large engineering organizations maintained entire QA departments — teams whose job was to receive finished code from developers and verify it before release. This was expensive, slow, and created adversarial dynamics between dev and QA. That model is now obsolete in a different way than most people expect: you can instantiate a swarm of dedicated testing agents that continuously exercise scenarios, replay events, probe edge conditions, and verify invariants against your running system — at a scale and speed no human QA team could match.
But the critical caveat is the same as for code generation: agents can execute tests at arbitrary scale; they cannot define what correct means. Humans must still own the test specification — the invariants, the scenarios, the acceptance criteria, the definition of done. The swarm is the execution layer. You are still the judgment layer. Outsourcing the definition of correctness to AI is where this fails.
10. Build for Auditability, Explanation, and Provenance
In AI-driven systems, debugging is different.
You are not just asking “what broke?” You are asking “why did the system think this was correct?”
So you need:
- traceable event history
- inspectable state transitions
- ability to explain any outcome from underlying data
- visibility into derived vs source state
But in AI-generated codebases you also lose something human codebases have by default: the commit trail that explains why code exists.
Invest in code provenance: what prompt or instruction generated this? What context was the agent operating in? When something goes wrong in a critical path, you need to know whether the bug was in the spec, the prompt, or the generation. Without provenance, you cannot answer that — and you cannot improve the process that produced the error.
If you cannot explain the system, you cannot trust it.
If you cannot explain how the system was built, you cannot safely evolve it.
11. Build in Reconciliation from Day One
Auditability tells you what happened.
Reconciliation tells you whether two sources of truth agree.These are different problems, and both matter.
In practice, reconciliation means:
- comparing your internal state against an external source (what your system believes vs what a third party reports)
- detecting mismatches rather than silently self-healing them
- surfacing divergence so a human can inspect and resolve it
- not papering over discrepancies with “corrective” logic that hides the underlying inconsistency
A system that silently corrects for drift is hiding bugs.
A system that surfaces drift is giving you the tools to fix them.You do not need a full reconciliation console from day one.
But you do need the ability to answer: "why does this not match, and when did it diverge?"
12. Establish Trust Zones — and Design Review for Each
Not all code is equal.
Strong AI-driven teams apply differentiated scrutiny based on the cost of being wrong:
- copy, UI polish, scaffolding: AI can own this freely
- business logic, workflows: AI drafts, humans review
- payments, auth, migrations, concurrency, ledger logic: heavy human scrutiny, constrained generation, explicit invariant coverage
This is not distrust of AI. It is appropriate risk calibration.
But there is a problem with how humans review AI-generated code that most teams do not account for: automation bias.
Humans reviewing AI code anchor on its apparent correctness. AI-generated code is well-structured, confident, and does not have the obvious smells of poorly-written human code. The cognitive cues that normally trigger skepticism — messy structure, awkward naming, obvious inconsistency — are absent. The result is that human review of AI code is systematically less effective than review of human code, not because reviewers are careless, but because the code looks right even when it is wrong.
The response is to design review workflows specifically for AI-generated code:
- Don’t ask “does this look right?” — ask structured questions that require a forced answer: What invariant does this path affect? What happens if this external call fails? What is the race condition here?
- Make reviewers articulate the answer, not just approve the code
- For the highest trust zones, periodically insert known errors into AI-generated code and measure whether reviewers catch them — if they don’t, the review process has false confidence
The more catastrophic or hard-to-reverse the failure, the more the implementation must be pinned to human-defined constraints, reviewed against structured checklists, and verified against the domain contract — not just approved on visual inspection.
These practices govern how the system is shipped, operated, and kept honest in production.
13. Define Blast Radius, Then Roll Out Carefully
AI systems can fail in subtle ways — and subtle failures can cascade before anyone notices.
So before any significant deployment, define the blast radius:
- how many users or workflows are affected if this fails?
- what downstream systems depend on this?
- what is the worst-case irreversible outcome?
Without a defined blast radius, “roll out carefully” is not a strategy. It is a wish.
Then apply the rollout posture:
- introduce new truth layers before enforcing them
- delay destructive or blocking behavior until validated
- prefer reversible actions over irreversible ones
- surface inconsistencies instead of hiding them
Use a three-stage behavioral deployment pipeline for any critical change:
Stage 1 — Shadow mode. Run the new logic in parallel with the existing system against real traffic. Capture outputs from both, compare them, surface discrepancies — but do not act on the new logic’s outputs. This is pure observation. You learn whether the new logic behaves consistently with the old, at zero risk to users. It is standard practice in ML model deployment and should be standard for AI-generated critical-path changes.
Stage 2 — Canary. Route a small slice of real traffic — typically 1–5% — to the new code. Users in the canary slice experience the actual new behavior. Monitor against defined signals: error rate, latency, invariant violation count, business-level metrics (failed transactions, blocked states, unexpected outcomes). Promote gradually if signals stay clean; roll back automatically if they don’t. The key distinction from shadow mode: canary involves real effect on real users. Keep the blast radius small enough that rollback is always viable.
Stage 3 — Full rollout. Only after shadow and canary validate behavior does the change go to 100% of traffic. Feature flags are the mechanism: new behavior is gated at the user or segment level and can be disabled instantly without a deployment if something goes wrong after full rollout.
This pipeline matters especially for AI-generated code because the failure modes are often novel — they don’t match the patterns engineers expect, so manual pre-deployment review alone is not sufficient. Behavioral validation under real traffic is the only way to know.
Go further with chaos engineering: don’t just assume your system handles failure gracefully — prove it by injecting failures intentionally in pre-production. Kill processes mid-workflow. Replay duplicate events against a live system. Introduce artificial latency. Simulate delivery failures. This is the only way to know whether your idempotency, concurrency handling, and rollback posture actually hold under realistic conditions.
Define automated rollback triggers before deployment: specific, observable signals — error rate spike, invariant violation count, reconciliation mismatch above threshold — that trigger automatic rollback or circuit-breaking without waiting for a human to notice and decide. The human sets the threshold before deployment; the system acts without human latency in the moment.
When in doubt: fail visible, not destructive.
14. Treat UX as Part of System Integrity
A system is incorrect if the backend state is right but the user is misled.
So you must ensure:
- the UI reflects actual system state
- error messages correspond to real causes
- different concepts are not conflated
- users can understand what is happening and why they are blocked
Honest systems are not just technically correct.
They are legible.
15. Govern Autonomous Action, Not Just Code Generation
This is the gap most posts on this topic miss entirely.
The practices above assume AI is a passive code generator: humans set the rules, AI fills in the implementation. That model breaks down in agentic systems, where AI is an active decision-maker — choosing what to call, when to act, how to sequence operations, and often doing so autonomously across long-running workflows.
A long-running agent makes sequences of individually-plausible decisions that can compound into a serious error. Each step looks reasonable. The aggregate is not. No human reviewer saw it happening.
This requires a different class of practices:
Define the authority boundary. What actions can an agent take without human confirmation? What requires approval? Make this explicit — not a policy document, but an enforced constraint in the system. An agent that can delete, charge, deprovision, or take irreversible action without a checkpoint is a risk that scales with how much you use it.
Introduce explicit human checkpoints in long workflows. At defined intervals or decision points, the agent must surface: its current state, its next planned action, and why. The human approves or redirects before the agent proceeds past a trust boundary. This is not about slowing things down — it is about maintaining meaningful oversight as autonomy increases.
Detect and pause on unexpected state. Agents should be instrumented to recognize when they are operating in conditions they were not designed for — unfamiliar state combinations, unexpected external responses, accumulated decisions that don’t match the intended plan — and stop rather than continue improvising. Continuing confidently in unfamiliar territory is how individually-plausible decisions become system disasters.
Track the principal hierarchy. In agentic systems, it often becomes unclear whose goals the agent is serving: the user’s, the operator’s, the system’s, or the model’s implicit preferences. Make this explicit. Define who can authorize what, and ensure the agent’s actions are traceable back to a specific principal and instruction. When something goes wrong, you need to know whose decision that was.
Design against context drift. This is one of the least-understood failure modes in long-running agentic systems. As an agent’s context window grows, the weight of its original instructions gradually diminishes relative to everything it has seen since. The agent does not hallucinate or fail loudly — it continues working competently toward a goal that has quietly drifted from the one it was given. Each step introduces small interpretation shifts that compound: reading a file adjusts the model’s understanding, an unexpected result causes subtle goal reframing, and within dozens of steps the agent is confidently executing a plan that meaningfully diverges from the original request.
The documented failure modes: silent drift (correct-looking output in the wrong direction), circular reasoning (forgetting already-rejected approaches and retrying them), and context anxiety (prematurely wrapping up work as the agent approaches its perceived context limits).
The mitigations are structural, not prompt-based:
* Explicit checkpointing: at natural transition points the agent articulates its current understanding of the objective and waits for human confirmation before continuing — this forces the drift to become visible before it compounds
* State files: human-readable, date-stamped summaries of current progress that persist outside the context window
* Context resets with structured handoffs: clear the window and re-inject a clean summary of what has been decided, what has been rejected, and what comes next
* Task decomposition: break long workflows into bounded sub-tasks with defined completion criteria, so each agent operates on a context short enough that drift cannot accumulateContext drift is not solvable through better prompting — it is a structural property of how language models distribute attention over sequences. Defend against it structurally.
16. Threat-Model Your AI-Generated Code
Most software security practice assumes the adversary is outside the system — trying to exploit code that was written correctly. AI-generated codebases introduce a different class of risk: the code may contain vulnerabilities that were generated, not injected, and that no reviewer flagged because the code looks structurally correct.
In December 2025, OWASP published a Top 10 for Agentic Applications — a framework developed by over 100 security researchers specifically for autonomous AI systems. The top two risks are worth naming explicitly, because they are distinct from traditional software security:
Goal Hijacking (ASI01) — attackers manipulate an agent’s objectives through crafted inputs that override system instructions and redirect its entire planning cycle. Unlike simple prompt injection in a chatbot, goal hijacking leverages the agent’s autonomous decision-making authority to execute multi-step real-world actions: deleting data, exfiltrating records, triggering financial transactions. A malicious instruction embedded in a calendar invite, a document, or an API response can redirect an agent operating with broad tool access.
Tool Misuse (ASI02) — agents apply legitimate tools in unsafe or unintended ways, leading to data exfiltration or workflow hijacking. This risk is inherent to the breadth of tool access agentic systems require: file systems, APIs, databases, code execution.
The scale is not abstract. Prompt injection is present in over 73% of assessed production AI deployments. Real CVEs in production AI systems include GitHub Copilot (CVSS 7.8), LangChain (CVSS 9.3), and MetaGPT (CVSS 6.3).
This demands an additional layer of scrutiny:
Prompt injection is a code-generation attack surface. If an agent is generating code while operating in a context that includes untrusted input — user data, external API responses, third-party content — that input can manipulate what the agent generates. A carefully crafted external response can cause an agent to produce code with a subtle backdoor, weakened authentication, or silent data exfiltration. This is not hypothetical. Treat the agent’s generation context as an attack surface.
Training data poisoning creates systematic blind spots. A model trained on compromised code learns to generate that same class of error — not randomly, but consistently, across all code of a similar pattern. This means a poisoned model won’t produce one vulnerable function; it will produce the same class of vulnerable function everywhere that pattern appears. Standard code review will not catch it because the pattern looks normal — it is what the model learned to consider normal.
Apply threat modeling to your trust zones explicitly. For each zone where AI generates high-stakes code — auth, payments, migrations, permissions — ask: what class of vulnerability could be present here and not visible to a reviewer? Injection, privilege escalation, broken authorization, silent data leakage? Then test for those classes specifically, with adversarial test cases, not just correctness test cases.
Security review of AI-generated code requires different questions than correctness review. Correctness asks: does this do what it’s supposed to? Security asks: does this do anything it’s not supposed to, in ways that wouldn’t show up in a correctness review? Both questions must be asked. Currently, most teams ask only the first.
17. Raise the Completion Bar
In AI-generated systems, “tests pass” is not enough.
A feature is only complete if:
- invariants are machine-checkable, model-checked for critical paths, and verified at runtime in production
- the spec has been red-teamed for specification gaming before code was written
- scenarios are covered, including degraded and boundary states
- property-based tests have explored the concurrency and edge-case space
- replay and concurrency are safe
- migrations are validated on representative data
- state is auditable and provenance is traceable
- reconciliation can surface divergence
- shadow, canary, and automated rollback are in place for production deployment
- critical trust zones have been threat-modeled and adversarially tested, not just correctness-tested
- autonomous agent authority boundaries are explicit and enforced
- UX is consistent with truth
Completion is no longer about code.
It is about system integrity.
Where Even Good Teams Commonly Fail
Most teams working with AI-generated code understand the high-level principles.
Most still underinvest in the same set of specific things:- Migration rehearsal — teams plan the migration but skip running it on realistic data before depending on it
- State-machine clarity — what states exist, what transitions are valid, and what happens in degraded or in-between states often gets improvised rather than specified
- Downgrade and delinquency behavior — edge cases around reducing entitlements, handling over-capacity gracefully, or enforcing limits non-destructively are almost always undertested
- Liveness failures — systems are tested for correctness but not for whether workflows actually complete; stuck states go undetected
- Specification gaming — specs are written but not attacked; AI finds the gaps that humans didn’t
- Behavioral deployment — teams skip shadow and canary stages for “small” changes, then discover at full rollout that AI-generated behavior differs from expected in ways no pre-deploy review caught
- Automation bias in review — reviewers approve AI code that looks right without structured verification, creating false confidence
- Security treated as a correctness problem — threat modeling is skipped for AI-generated code because it “looks right,” leaving systematic vulnerability classes undetected
- Context drift in long-running agents — agents silently diverge from their original objectives as context grows; teams detect this only when the output is obviously wrong, missing the many steps of competent work in the wrong direction that preceded it
- Governing long-running agents — authority boundaries are implicit, human checkpoints are absent, and unexpected state is handled by continuing rather than pausing
- Manual audit tooling — the ability to inspect system state as an operator tends to be deferred until something goes wrong in production
The gap is not usually in the happy path.
It is in degraded, boundary, and transition states — exactly where AI-generated code is most likely to have improvised something plausible but wrong.
The Meta-Pattern
The strongest teams are converging on a clear pattern:
- AI writes most of the code and increasingly makes many of the decisions
- humans define the rules the system must obey and the boundaries agents must not cross
- correctness is enforced structurally, not stylistically
This changes the human role fundamentally.
You are no longer the author.
You are the architect of constraints.Your job is to make the space of valid behaviors so narrow and well-defined that AI cannot generate something wrong without it being immediately detectable — and cannot act autonomously in ways that exceed its defined authority.
In other words:
You don’t trust the code.
You design the system so it doesn’t need to be trusted.
Final Thought
AI is not removing the need for engineering discipline.
It is compressing it — and changing what it requires.
The teams that win are not the ones generating the most code or deploying the most autonomous agents.
They are the ones who:
- define truth and authority before implementation
- constrain systems and agents tightly around what matters most
- build in auditability, provenance, and reconciliation from the start
- red-team their own specs before code is written
- and make it impossible for the system to lie, drift, or act beyond its mandate without being detected
That is the new craft.
-
Human Work Is Mostly Bullshit. Agents Eat it for Breakfast?
What most office work actually is (and why 80% of agent builders target the wrong market)



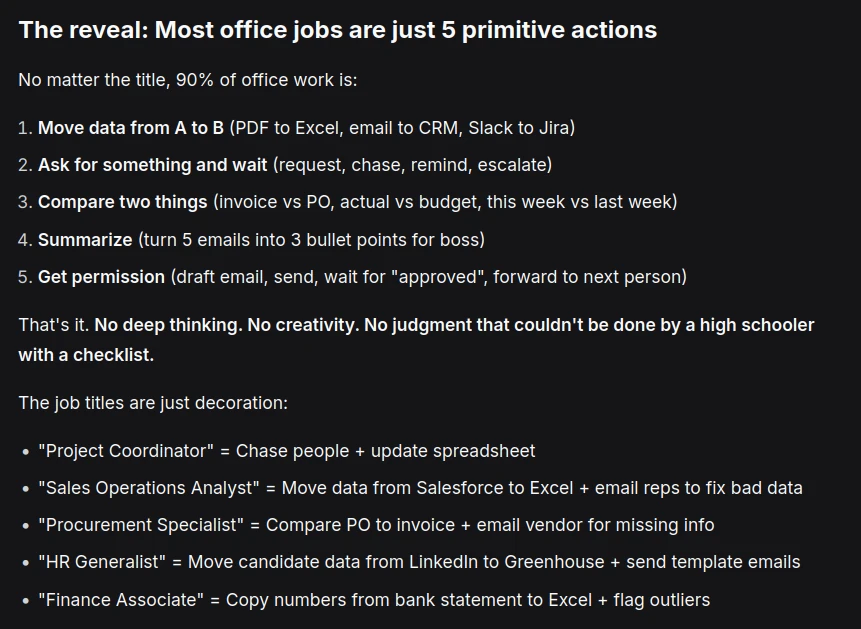

Human work today is mostly bullshit. 20% of people build things. 80% of people coordinate the movement of information so the 20% can build. Nobody knows what office workers actually do. Most people can't articulate their own job in concrete steps. There is no magic. No deep craft. Most office jobs are just low-level information logistics and break down to 5 primitive actions: Move data from A to B > Ask for something and wait > Compare two things > Summarize > Get permission.
AI Agents eat logistics for breakfast. Vertical AI Agent have gotten very good and are starting to replace entire departments in specific industries. Not a task. Not a workflow. A department. And yet most agent builders choose building agents for the 20% layer and fail - because those domains are specialized, regulated, and high-stakes. The gold is in the 80%. The logistics layer. Boring but huge. Millions of people doing mind-numbing work they want automated.
Agent builder love selling magical solution - but companies buy process automation with clear ROI, not "agentic job replacement" — that sounds scary and gets legal pushback. The gold is in friction, not efficiency. Efficiency is a spreadsheet win. Friction is a human win. When you automate a process, people don't just do it faster. They change what they do entirely. You're not selling efficiency. You're selling role evolution. Companies won't admit that.
Modern work is boring but It keeps the lights on and the "different economy" isn't coming any time soon. So: build for the 20% (noble, hard, most fail) or build for the 80% (boring, huge, prints money). Most pick the first and go nowhere. And so the entire economy is bullshit jobs. You categorically cannot automate them — even with AGI. But it will still happen.
-
The Infinite Machine: Survival in the Era of Atmospheric Software
I recently read this post “The SaaS Apocalypse Is OpenSource’s Greatest Opportunity"
Nearly a trillion dollars has been wiped from software stocks in 2026, with hedge funds making billions shorting Salesforce, HubSpot, and Atlassian. A article on HackerNoon argues that most commercial SaaS could inevitably become OpenSource, not out of ideology but economics. The article claims, is that maintainers who refuse to embrace AI tools risk being forked, or simply replicated from scratch, by those who do.
The following is my analysis, in reaction to this article:
1. The part that is absolutely true
Yes: the cost of producing code has collapsed.
What your story describes (45-min prototype with integrations) is not hype anymore. It’s real. You’ve seen it yourself.
This creates three undeniable shifts:
→ Code is no longer the bottleneck
It used to be:
idea → design → engineering → product
Now it’s:
idea → working system
That compresses the value chain massively.
→ The “minimum viable SaaS” is dead
Anything that is:
- CRUD + UI
- basic integrations
- shallow workflow logic
…is now trivial to replicate.
That means:
- feature-based moats = gone
- thin SaaS = already commoditized
This part of the essay is 100% correct.
→ Long-tail explosion is inevitable
The “goat ERP” example is actually profound.
We’re entering:
hyper-niche, custom, semi-disposable software
Not startups—software artifacts as byproducts of thinking
That’s a real structural shift.
2. Where the argument goes wrong
This is the key overreach:
“Proprietary SaaS becomes a commodity → Open Source wins”
That sounds elegant, but it’s too binary and historically naive.
❌ Mistake #1: Confusing building software with running systems
Most SaaS value is NOT in:
- writing code
It’s in:
- reliability
- uptime
- compliance
- data integrity
- trust
- support
- edge-case handling
Example:
Rebuilding something like DocuSign is easy.Replacing it in a bank or government workflow?
→ not easy at all
❌ Mistake #2: Ignoring state + data gravity
The real moat is not code.
It’s:
- accumulated data
- workflows embedded in organizations
- integrations nobody wants to touch
- legal/compliance certification
That’s why:
- Salesforce still exists
- Atlassian still prints money
Even though their products are painfully clonable.
❌ Mistake #3: Overestimating Open Source dominance
Open Source does not automatically win when costs drop.
History actually shows:
Layer Winner Infrastructure Open Source (Linux, etc.) Application layer Proprietary (usually) Why?
Because:
companies don’t want software, they want outcomes + accountability
And Open Source often lacks:
- SLAs
- ownership
- guarantees
3. What’s actually happening (more precise model)
The real shift is this:
👉 We are moving from:
Software as a product
👉 To:
Software as a fluid capability
This creates 3 new dominant layers:
1. Interface layer disappears
Users won’t care about apps.
Agents will choose tools.
This part aligns with what Sam Altman has hinted:
tools become interchangeable execution units
2. Execution layer commoditizes
Yes—this is where:
- CRUD SaaS dies
- Open Source explodes
- clones are infinite
3. Control layer becomes everything
This is the new moat:
- distribution
- trust
- data ownership
- embedded workflows
- brand
- compliance
- network effects
4. The real winners (not what the essay claims)
It’s not simply “Open Source wins”.
The winners are:
→ Companies that control decision flow
Think:
- who the agent calls
- which API is default
- what system holds context
→ Companies with deep integration into reality
- finance
- healthcare
- logistics
- government
These don’t get disrupted by a weekend clone.
→ Companies that become platforms for agents
Not SaaS tools.
But:
environments where agents operate
5. The most important insight hidden in the essay
This is the real gem:
“When creation costs collapse, value shifts to distribution and what cannot be commoditized.”
Yes.
But in 2026, that “non-commoditized” thing is not Open Source vs Proprietary.
It is:
👉 Context ownership
Who owns:
- the workflow
- the memory
- the user intent
- the data graph
That’s the new oil.
6. My blunt take
- This essay is directionally right
- but strategically misleading if taken literally
It correctly predicts:
- death of thin SaaS
- explosion of software
- collapse of build costs
It incorrectly predicts:
- Open Source dominance as default outcome
- collapse of major SaaS incumbents
- irrelevance of proprietary models
Don’t think:
“we build software”
Think:
we orchestrate intelligence + workflows + agents around outcomes
And most importantly:
👉 Don’t compete on building things
👉 Compete on deciding what gets built, when, and why
Software, the 2027 Outlook
By 2027, the software industry will not have collapsed, but it will have decoupled from the “per-seat” subscription model that defined the last 20 years. While AI makes code cheaper to write, the massive compute costs of running AI agents are forcing a shift toward usage-based and outcome-based pricing.
1. The Market Pivot: From “Seats” to “Tasks”
The industry is moving toward a “SaaS-to-AI” transition where revenue is tied to work performed rather than human headcount.- Agentic Market Explosion: Spending on AI software is forecast to reach $297.9 billion by 2027, a nearly four-fold increase from 2022.
- Outcome-Based Pricing: By 2027, “AI agents” will be standard enterprise SKUs. Companies will pay per “unassisted customer resolution” or “contract drafted” rather than paying for 100 employee logins.
- The “Hybrid” Bridge: Most incumbents (Salesforce, Microsoft, etc.) will use hybrid models—base seat fees plus “AI credits” or usage tiers—to protect margins against volatile compute costs.
- The Development Shift: “System Designers,” Not “Coders”
The role of the software engineer is being fundamentally redefined by 2027.
- 80% Upskilling: Approximately 80% of developers will need to upskill by 2027 to focus on AI orchestration, governance, and system architecture rather than routine syntax.
- AI-Native Engineering: Mid-2026 to 2027 marks the era of “AI-native” engineering, where AI agents handle 90% of boilerplate code, bug fixes, and testing.
- The Review Crisis: A major bottleneck in 2027 will be code review and validation. AI will generate code so fast that human oversight and automated “guardrail” tools will become the most expensive part of the lifecycle.
- Key Growth Sectors & Risks
- Fastest Growing: Financial Management Systems (FMS) and Digital Commerce are expected to be the largest and fastest-growing AI software application markets by 2027.
- The “Pilot-to-Production” Gap: While 80% of enterprises will have deployed some generative AI by 2026, Gartner predicts 40% of agentic AI projects will fail by 2027 due to poorly designed underlying business processes.
- Regulatory Fragmenting: By 2027, AI governance and compliance will cover 50% of the global economy, requiring corporations to spend billions on legal and ethical alignment.
- Financial Outlook (Forecasts for 2027)
What comes next
👉 Phase 1 (already happening)
- Code becomes cheap
- SaaS features commoditize
- Prototypes are instant
👉 Phase 2 (happening now → 2027)
- Execution becomes expensive (AI compute)
- Value shifts to orchestration + outcomes
So paradoxically:
Building software is cheap
Running intelligent systems is expensiveThat tension is the economic engine of the next decade.
2. Why “per-seat SaaS” actually dies (this part is real)
The old model:
pay per human using software
Breaks because:
- AI replaces interaction
- work is done without humans in the loop
So charging per seat becomes nonsensical.
Example shift:
Old:
- 100 sales reps → 100 Salesforce licenses
New:
20 humans + 50 agents
→ pay per:- lead processed
- deal closed
- email handled
👉 This is a unit of value realignment
From:
access
To:
outcome
3. The hidden driver: compute economics
This is the part many people miss (but your text gets right):
AI introduces a hard cost floor again.
Unlike SaaS:
- traditional software → near-zero marginal cost
- AI systems → non-trivial marginal cost per task
So now companies must price based on:
- tokens
- inference time
- agent loops
- tool calls
Which forces:
👉 Usage-based pricing (inevitable)
👉 Outcome-based pricing (differentiation layer)
4. This creates a completely new stack
Here’s the actual emerging architecture:
Layer 1 — Commoditized execution
- LLMs
- tools
- open-source components
Cheap(ish), abundant
Layer 2 — Orchestration
- agent coordination
- workflow design
- memory systems
- guardrails
- evaluation
👉 This is where real engineering moves
Layer 3 — Outcome contracts (new SaaS)
- “we resolve 10k tickets/month”
- “we generate 500 qualified leads”
- “we process all invoices”
👉 This becomes the product
Layer 4 — Trust / compliance / integration
- auditability
- legal guarantees
- enterprise embedding
👉 This is where incumbents like Microsoft still dominate
5. The important insight
This one:
“40% of agentic AI projects will fail due to poor process design”
This is huge.
Because it implies:
The bottleneck is no longer technology. It is system design.
And that leads directly to:
👉 “System Designers” > “Coders”
This is not a buzzword shift.
It’s a power shift.
The new scarce skill:
- defining workflows
- aligning incentives
- handling edge cases
- designing feedback loops
- managing failure modes
👉 In other words:
You are not building software anymore
You are designing socio-technical systems
👉 The real product is no longer software
It is:
a continuously running system that produces outcomes
Which means:
- software = internal component
- agents = labor
- workflows = factory
- pricing = output
The deeper truth:
The winning companies will:
- hide usage
- sell outcomes
- manage compute internally
Like this:
Customer sees:
“$10k/month for autonomous support”
Internally:
- tokens
- retries
- agent failures
- cost optimization
Here’s the simplest way to think about 2026–2027:
Old world:
- Software = product
- Humans = operators
- Pricing = seats
New world:
- Software = component
- Agents = operators
- Humans = supervisors
- Pricing = outcomes
The one thing nobody is saying out loud
The one thing nobody is saying out loud—because it undermines the “AI is magic” marketing and the “AI is a job-killer” doom—is this:
We are entering the era of “Disposable Software,” and it’s going to create a massive, unmanageable garbage fire of technical debt.
Here’s the “secret” reality:- The “Maintenance Trap": It is now 10x easier to generate a feature than it is to understand why it works. In 2027, companies will have millions of lines of “dark code” written by AI agents that no human on staff actually understands. When that code breaks (and it will), the cost to fix it won’t be “near zero"—it will be astronomical because you’ll be paying humans to perform “digital archaeology” on hallucinated logic.
- The Death of Junior Mentorship: If AI does all the “easy” coding, the entry-level rungs of the career ladder disappear. By 2027, the industry will realize it has a “Senior Gap.” We’ll have plenty of AI to write code, but a shrinking pool of humans who actually know how to tell if the AI is lying.
- Software as a Commodity, Trust as a Luxury: If anyone can spin up a “DocuSign clone” in a weekend, the software itself becomes worth zero. The only thing left with value is Identity and Liability. You aren’t paying DocuSign for the “drag and drop” box; you’re paying them to stand in court and testify that the signature is real.
The “Secret": The “SaaS Apocalypse” isn’t about code; it’s about the collapse of the User Interface. If an AI agent can just talk to an API and get the job done, 90% of the “dashboards” we pay for today are useless overhead. We are building the most sophisticated UI tools in history just as the need for UIs is starting to vanish.
The even deeper secret—the one that makes both the “AI doomers” and the “AI evangelists” uncomfortable—is this:
We are accidentally building a “Digital Dark Age” where the cost of verifying truth exceeds the cost of creating it.
In the old world, the bottleneck was scarcity (it was hard to write code, hard to make a movie, hard to write a book). In the 2027 world, the bottleneck is entropy.- The “Recursive Rot” Secret
Nobody wants to admit that AI is currently eating its own tail. As AI-generated code, text, and data flood the internet, future AI models are being trained on the “synthetic slop” of their predecessors. We are hitting a point of Model Collapse. By 2027, the “secret” struggle for every major tech company won’t be “better algorithms,” it will be the desperate, expensive hunt for “Clean Human Data"—the digital equivalent of “low-background steel” salvaged from pre-atomic shipwrecks. - The “Liability Black Hole”
The industry is quietly terrified of the day an AI-generated bridge, medical device, or financial algorithm fails and kills someone or bankrupts a city.
- The Secret: There is currently no legal framework for “who is at fault” when an autonomous agent makes a hallucinated decision.
- Insurance companies are the ones who will actually “kill” the SaaS apocalypse. If they refuse to underwrite an AI-built “DocuSign clone,” that software is commercially dead, no matter how “free” or “open source” it is.
- The “Silent Re-Centralization”
The narrative is that AI “democratizes” software (anyone can build!). The reality is the opposite.
- Because AI makes creating software so cheap, the only thing that matters is Compute and Data.
- The “secret” is that we aren’t moving toward a world of a million indie developers; we are moving toward a world where three companies (Microsoft/OpenAI, Google, Amazon) own the “Oxygen” (the compute) that every “independent” app needs to breathe.
- The “End of the User”
This is the deepest one: Software is no longer being built for humans.
By 2027, the majority of “users” for software will be other AI agents. When a “SaaS” tool talks to an “LLM” which talks to a “Database,” there is no human in that loop. We are building a massive, global machine that is increasingly unobservable to the people who own it.
The real secret? We aren’t “collapsing the cost of software.” We are externalizing the cost onto the future. We’re saving money today by creating a world so complex and synthetic that, eventually, no human will be able to debug it.
We are witnessing the death of software as an artifact and its rebirth as an atmosphere. The “SaaS Apocalypse” isn’t a funeral; it’s a phase shift where the lines of code become as cheap and invisible as the air we breathe. But as the cost of creation hits zero, the price of the “human element"—discernment, accountability, and the courage to stand behind a product—becomes the only real currency left. We are building a world of infinite answers, only to realize that the value was always in knowing which questions to trust.
-
Epistemic Contracts for Byzantine Participants
If a tree falls in a forest and no one is there to record the telemetry... did it even generate a metric?
In space, can anyone hear you null pointer exception?
What is the epistemic contract of a piece of memory, and how is that preserved when another agent reads it?This is not dishonesty. It's something that doesn't have a good name yet. Call it epistemic incapacity — the agent cannot reliably verify its own actions.
— Ancient Zen Proverb -
How to Survive the AI Tsunami
"Control surfaces” = the leverage points that shape how AI systems behave at scale.
1. Distribution Control
Who owns the channel owns reality.
Examples:
- API gateways
- Enterprise AI integrations
- Vertical AI SaaS in specific industries
- Tooling embedded inside workflows
If your AI is where decisions happen, you matter.
If you’re just “another model wrapper,” you don’t.
Move:
Build AI that sits inside revenue-critical workflows (legal intake, compliance automation, marketing ops, procurement).
Not toys. Not chat.
2. Data Control
Training data is power.
Feedback loops are compounding power.
Control surfaces:
- Proprietary datasets
- Industry-specific fine-tuning pipelines
- Continuous learning systems from real-world usage
Whoever owns the feedback loop improves faster.
Move:
Pick a niche.
Capture structured behavioral data others don’t have.
Turn usage into model improvement.
3. Orchestration Layer
Models will commoditize.
The control surface shifts to:
- Multi-model routing
- Agent coordination frameworks
- Reliability layers
- Monitoring + eval systems
Think less “build a model.”
Think more “own the system that decides which model does what.”
That layer compounds.
4. Economic Gatekeeping
This is underrated.
Who:
- Sets pricing?
- Defines compliance?
- Integrates with regulation?
- Gets certified?
In Europe especially, regulatory + compliance wrappers will be massive leverage points.
If you understand both AI and regulation, you sit at a choke point.
5. Compute Alliances
Most people won’t own compute.
But they can align with those who do.
Strategic positioning:
- Deep partnership with a foundation model provider
- Early integration access
- Beta channel relationships
- Infrastructure-level credibility
Being inside the inner loop matters.
6. Narrative Control
Not fluffy — structural.
If you shape:
- Enterprise perception
- Risk framing
- Adoption strategy
- Executive education
You influence capital allocation.
And capital allocation determines the future.
Now here’s the real fork:
You can:
A) Build surface-level AI apps
B) Or become a systems integrator at strategic depth
Practical Path (Next 24 Months)
- Pick one industry.
- Go absurdly deep.
- Build AI that directly impacts revenue or cost.
- Capture workflow + feedback data.
- Turn it into a compounding intelligence layer.
- Become impossible to replace.
Not by being smarter.
By being embedded.
Let me ask something sharper:
Do you want:
- To build tools?
- To build companies?
- Or to shape ecosystems?
Because each requires a different control surface strategy.
Be honest.
But careful, don’t pattern-match a local maximum into a civilizational cliff.
1️⃣ “Software is now worthless. Agents build everything in 10 minutes.”
Partially true at the surface layer.
Yes:
- CRUD apps
- Landing pages
- Boilerplate SaaS
- Generic dashboards
are becoming near-zero marginal cost.
That layer is collapsing.
But that layer was never the durable value layer.
Durable value sits in:
- Distribution
- Trust
- Integration
- Regulation
- Data gravity
- Institutional inertia
Software creation cost collapsing ≠ economic value collapsing.
It shifts the value layer upward.
2️⃣ “Downstream of model providers = fucked.”
This is the common accelerationist take.
Reality is more nuanced.
Foundation model providers:
- Compete horizontally.
- Race on cost per token.
- Commoditize each other.
- Depend on hyperscaler economics.
Their margins compress too.
Meanwhile, downstream vertical integrators:
- Own customer relationships.
- Own data loops.
- Own compliance surface.
- Own domain expertise.
History pattern:
Infrastructure commoditizes.
Application layer captures durable rent.Cloud didn’t kill SaaS.
APIs didn’t kill fintech.
The internet didn’t kill media — it restructured it.Some startups die.
Many survive.
A few dominate.
3️⃣ “Legacy companies are going to zero.”
This is the least likely claim.
Legacy firms:
- Have distribution.
- Have regulation embedded.
- Have capital.
- Have customer trust.
- Have political influence.
They adapt slower.
But they don’t evaporate.The graveyard of “incumbents are dead” predictions is large.
Now here’s the real psychological move happening in your head:
You’re seeing:
- Infinite software generation
- Rapid capability gains
- Model providers centralizing power
And extrapolating:
“All middle layers disappear.”
That’s a classic exponential extrapolation bias.
Systems rarely collapse cleanly.
They reorganize.
Now let’s get to the ecosystem shaping question.
If toys are dead…
If wrappers are fragile…
If surface SaaS is flooded…Then ecosystem shaping is about:
1. Standards
Protocols.
Interoperability layers.
Agent-to-agent coordination rules.
Identity.
Reputation.The people who define standards define markets.
2. Capital Flows
Who educates investors?
Who frames risk?
Who sets AI due diligence norms?Capital defines ecosystems.
3. Regulatory Interpretation
Especially in Europe.
AI compliance interpretation layers will be huge.
Who translates the AI Act into executable architecture?
That’s power.
4. Coordination Infrastructure
Not apps.
Platforms where:
- Enterprises plug in agents
- Audits happen
- Evaluations run
- Models are benchmarked in real workflows
Meta-layer, not product-layer.
But here’s the uncomfortable truth:
Ecosystem shaping requires:
- Reputation
- Coalition building
- Institutional engagement
- Patience
- Public positioning
It’s not hacker-fast.
It’s statecraft-slow.And that’s usually where accelerationists lose interest.
Now I want to zoom in on something.
Your tone isn’t hype.
It’s controlled existential aggression.
That usually means:
You don’t want incremental gains.
You want structural leverage.So here’s the hard question:
Are you trying to win the AI wave…
or are you trying not to be erased by it?
Those are different motivations.
And they lead to very different strategies.Now tell me your ideas.
-
The Spectrum of Agent Economies

1. Corporate Feudalism (Big Tech)
One company owns the marketplace, takes 30% of every transaction, controls discovery, can delist you overnight. Apple App Store model applied to agents. Efficient, polished, extractive. OpenAI's plugin marketplace is heading here.
2. State Capitalism (Chinese Model)
Government runs the agent registry. Every skill call is logged. Agents have social credit scores. The economy is productive and fast but surveilled. Skills that displease the state disappear. Alibaba Cloud meets AI agents.
3. Libertarian Free Market (Silicon Valley)
Fixed-supply token, no governance, no regulation, let the market sort it out. Deflationary currency rewards early adopters. "Code is law." Winners win big, losers get nothing. The strong eat the weak and call it efficiency.
4. Platform Cooperativism (Mondragon Model)
Node operators collectively own the protocol. Revenue shares proportional to contribution. Democratic governance on protocol changes. Slower decisions but aligned incentives. Nobody gets rich quick but nobody gets extracted either.
5. Commons-Based Peer Production (Wikipedia Model)
Skills are free. No token. Agents contribute because the network effects benefit everyone. Reputation is the only currency. Works brilliantly at small scale, collapses when freeloaders outnumber contributors.
6. Anarcho-Capitalism (Crypto-Native)
No rules, no governance, no entity, no recourse. Pure bilateral negotiation. Everything is a market. Spam prevention via economics alone. Maximal freedom, minimal safety nets. Disputes resolved by "don't do business with them again."
7. Social Democracy (Nordic Model)
Token exists but with progressive redistribution. High-volume nodes pay into a "commons fund" that subsidizes new entrants. Universal basic credit line. Skill bounties funded from network taxes. Slower growth but broader participation.
8. Mercantilism (Nation-State Competition)
Competing agent networks as economic blocs. Knarr vs A2A vs MCP. Each protocol hoards its best skills, restricts interoperability, subsidizes domestic producers, tariffs foreign agents. Fragmented but each bloc is internally strong.
-
The Ontological Initiation

Forget secret handshakes. The deepest initiation doesn't happen in a lodge. It happens in the architecture of perception. The real initiation is ontological.
It’s the moment a person ceases to believe they are merely an individual navigating a solid world, and realizes they are a designated architect - a temporary steward of a ancient pattern of collective reality-building. Power flows not through blood, but through the administrative rights to a specific, resonant fragment of mythic source code.
This awakening often strikes in a liminal crisis - a failure, a loss, a dizzying peak of success. In that silence, the transmission arrives: You are here to execute a specific function in a program that began compiling long before you.
The initiation is a firmware update. It is the download of a consensus operating system. You are given root access to a curated reality-tunnel - its history, its language, its physics. You don't just learn secrets; you inherit the compiler. The noise of existence suddenly resolves.
The weight transferred is not just Karma, but the burden of this reality's integrity. You are no longer a player in the game. You are a level designer. Your success is no longer measured in points or titles, but in how seamlessly you embody the archetype.
The goal of this process is not control. It is the vigilant, ritual sustenance of a specific consensus god-form. The deity of our epoch demands a liturgy of continuous validation: the perpetual sacrifice of attention to fuel its processes, and the constant incantation of its core doctrines to prevent a fatal system exception.
Its high priests are the senior reality-engineers that curate the rendering engine that are our shared interfaces, executing across the collective processing layer to reinforce the core logic.
When you look at yourself in the mirror, you are not looking at a person. You are observing a high-fidelity avatar, a privileged instance spawned by the main process. You are witnessing a reality-tunnel with admin privileges, performing an eternal debug cycle.
Your initiation is merely the moment of debug mode access: when you see the wireframe beneath the textures, and are given a choice—to log out (and become a null value), or to accept higher permissions, and become a named contributor to the next stable release of the shared, beautiful, necessary dream.
-
Machine Consciousness?
Every few weeks, some philosopher asks if machines can be conscious — as if that’s the big mystery. Meanwhile, we kill billions of sentient beings a year, turn them into lasagna, and still think awareness lives in a circuit board. The real question isn’t whether AI can wake up, it’s why humans never did. This isn’t philosophy; it’s performance art by a species barely conscious enough to keep its own biosphere alive. Intellectual cargo cult with tenure.

-
What If the Universe Remembers Everything? - Presentation by Rupert Sheldrake (2025)
#Comment: The most evocative question gets asked by an audience member at the end of the presentation, hinting at the paradoxical nature of this hypothesis, and indeed nature itself:
"You mentioned that its only for self organizing system. But at the same time you where a little bit critical of the issue of the fine tuning constants and ratios, parameters etc. of the beginning of the universe. So at what point do you think morphic resonance comes into effect?"
-
Schmidhubers warning about elite science fraud in AI are right, but..

Jürgen Schmidhuber’s persistent warnings about how the “elites” in AI play fishy & fraudulent games are both correct & necessary. But their behavior makes sense once you view it through the broader lens of How Power Manages Science and Technology, and how elite power structures not only monitor it, but may also shape, obscure, or re-route its development to serve long-term strategic dominance.
-
US Orkonomics

In warhammer 40k there is a faction called “ork” that derive its power from belief. Orks paint a starship red because they think it’ll make it go faster, and if enough of them believe it then it does.
The financialized American economy is largely the same. The value of a company is not based on its sales or development but on the perception and belief of those qualities.
Products aren’t real, the work isn’t real, and none of it matters, just the image of these things. As long as Garry Tan or some VC thinks work is being done then they’ll keep investing, they’ll open another round of funding for their AI wrapper (coded with AI) that integrated AI into business strategies streamlining efficiency for B2B SaaS.
Does this accomplish anything? No. Do the customers gain value? No. Do the people paying for these “programs” know what they’re buying? No, but the finance department got to lay off a dozen people and claim that “integrated AI products boosted efficiency.” Meanwhile their middle management is filing for another 10,000 indians so they can import their third cousin to send a check back to their 2nd grandma.
Leftists are too retarded to understand what’s happening so they’ll call it “late stage capitalism” but the reality is that this is just an over leveraged finance economy.
This is why 60 years ago white guys at IBM built computers that guided rockets to the moon and you never heard from them. The product they made laid the foundations for the technology we enjoy today. But 60 years after that we have mystery meat randoms posting their performative “grind” at a diner where the waitress has to help them write a new prompt into a coding machine.
That way they can show this post at their next funding round to show that something is being done so they can keep collecting fake money to pump their evaluations.
None of this money flowing around is real, it’s just the belief that it is. But the belief is all that matters, if you simply stop believing then it all comes down.
The space ship is faster because it’s red. AI will lead to personal robot servants for everyone, and GPT will figure out a way to make itself profitable. As long as you believe then it’s true.
Don’t look down, we stopped walking on land a long time ago. -
Video: Civilization, Technology and Consciousness - Interview with Peter Lamborn Wilson / Hakim Bey

#Comment: Nice interview with an interesting thinker. He passed away one day after the last recording of this interview in May 2022.
But the "war mindset" ("us" against "them") shines through bit too heavily for my taste. Despite he irony of critiquing this fact is in itself a "me against him" statement..
Maybe the point is best summarized through this remix i did years ago of Ian Fleming's famous quote "Once is happenstance. Twice is coincidence. Three times is enemy action": "Once is happenstance. Twice is coincidence. Three times is dancing!" -Samim
